Return to lecture notes index
February 19, 2008 (Lecture 10)
gdb
We went through a quick gdb example. The upshot is this. To enable debugging,
use the "-g flag" to gcc. This tells gcc to include in the executible file,
almost as a comment at the end, a mapping from each chunk of assembly back
to the line of source code that generated it.
After recompiling with the -g flag, we ran our program in gdb. To
do this for our example, named "example", we typed "gdb example"
Once at the "gdb" prompt, we made use fo the following commands:
- break {linenumber} -- sets a break point at that line
- break {file}.c:{linenumber} -- sets a break point at that line
- break {function} -- sets a breakpoint at the start fo that function
- clear {N} -- clear the breakpoint set at line N
- cont -- continue to run after a breakpoint
- list -- list the code surrounding the current point of execution
- print {X} -- print out the value of expression X, which might
as simple as a variable
- run -- starts the program running within the debugger
- where -- show the call stack
We observed that gdb printed things the "Right way" by using the type
information, but that things could be cast to get it to print things
differently. We also saw that gdb has no trouble with multiple files
and can easily inspect arrays using either pointer or array notation.
Multidimensional Arrays, 2D Arrays, Specifically
The C Language supports multidimensional arrays. I don't know if there
is a hard limit in the standard, or a practical limit adopted by the
compiler -- but, in practice, you can have as many dimensions as you'd
like.
The syntax of the eclaration of a multidimensional array is probably
pretty unsurprising. It is basically an extension of the syntax for
a one-dimensional array:
int numbers[10]; /* a one-dimensional array */
char names[10][100]; /* a two-dimensional array */
unsigned int cube[10][10][10]; /* a three dimensional array */
And, once declared, the values are accessed exactly as one might expect:
strcpy (names[5], "Greg"); /* 'Greg\0' is stored into the array at row 5 */
names[5][0] = 'G';
names[5][1] = 'r';
names[5][2] = 'e';
names[5][3] = 'g';
names[5][4] = '\0';
cube[2][4][6] = 17;
So, how are multi-dimensional arrays represented within memory? When this
question was asked, some folks suggested as arrays of pointers to arrays
(of pointers to arrays, of pointers to arrays...). And, this approach
could work. But, it isn't actually what C does.
And, there are a few reasons for this. The first one is that managing a
data structure that complicated is a bit much for a language feature,
especially in a language designed to be as "close to the ground" as C.
If arrays were to be implemented that way, especially in a "low high-level
language" like C, they'd be implemented in a library, not as a first-class
language feature. Second, implementing arrays like that would almost
certainly require some form of garbage collection, something C doesn't
otherwise have. A call to free() woudl have to do more than free the one
pointer it was given -- it would have to play chase. This would be a case
of making the comon case slow to support the exception. And the third,
which you'll take a closer look at in 15-213, is that scattering arrays
in memory, rather than keeping them close together, could, especially for
smaller arrays, hurt memory performance.
So, what C really needs to do to keep things fast and simple is to
project a multi-dimensional array into a one-dimensionaly memory. And,
this is exactly what it does. We'll take a look at the case of a
two-dimensional array. But, it extends to higher dimensions, too.
We project a two-dimensional array into a one dimensional array by
taking it apart row-by-row or column-by-column. We then place these
parts, either rows or columns, next to each other in memory. When we
keep rows intact, and place rows, whole, next to each other in memory,
this is call row-major ordering. When we break apart the rows,
in order to keep the columns intact, and place the columns next to
each other in memory, we call this column-major ordering.
Most compilers use row-major ordering. There is no rule about this. But,
as it turns out, memory performs better if you use the vectorization
that most closely matches the way the data is used. In other words, if the
user of the data is most likely to move left-to-right through rows,
row-major ordering will perform better than column-major ordering. If,
however, the user is more likely to charge up or down columns than across
rows, column-major ordering is likely to lead to better memory performance.
The reason for this has to do with the way cache memory is managed
within the system. You'll learn all about this, and even do some optimization
by hand, in 15-213.
Regardless, as it turns out, the most common case of arrays with more than
one dimension is arrays with two dimensions. And, when it comes to
to dimensional arrays they are more often traversed across ross than
up or down columns. As a result, most comilers use row-major ordering.
So, let's take a look at the projection of a two-dimensional array into
one-dimensional memory using row-major ordering:
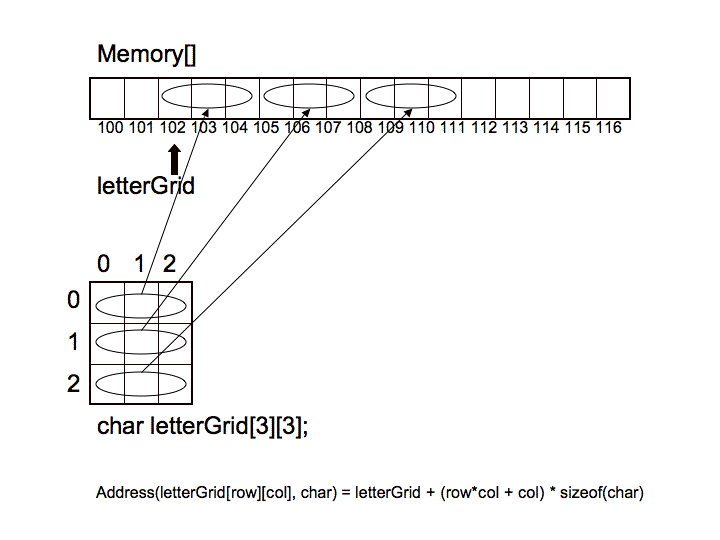
Notice how the 2D array was projected into memory. Take specific
note of the formula used to perform the projection:
Address(arrayStart, elementType, #rows, row, col) = arrayStart + (row*#cols + col)*sizeof(elementType)
If we think about it, this formula makes sense because we first move
to the beginning of the correct row, by skipping over prior rows,
each of which has the prescribed number of columns, and then by moving
forward to the correct offset, the correct column position, within the
desired row. This is, of course, done in one computation and therefor
in constant time. The complexity of the computation is linear with
respect to the number of dimensions.
Formatted File Input and Output
For our purposes, C has two forms of file I/O: formatted and
low-level. Today we'll talk about formatted I/O. Soon, we'll
learn about low-level I/O. But, especially for those of you coming
from Java, you'l find that both are very refreshing. They are simple,
to the point, and all-around a pleasure to use.
In C, as in many other languages and environments, interaction with the
file system is with a logical representation of a file, sometimes
known as a file handle. C uses a session-based model.
Under this model, a file-handle is associated with a particular file
and then continues to be associated with this file until the association
is explicitly broken. During the time that the session is open, it
can maintain some infomration about the state of the file and its use.
With respect to formatted I/O, the file handle is a so-called
file pointer declared as, FILE *. An fopen()
establishes the session by allocating the FILE object and
associating it with the poiner. An fclose() ends the session
and frees the actual FILE object.
In between the fopen() and fclose() calls, the file pointer can be used
to access the file. We'll explore more of the library a bit later this
semester, but for right now, we'll look at three functions:
- fprintf()
- fscanf()
- fgets()
- fputs()
fopen(), fclose(), fputs(), fgets()
Let's begin with a simple example that illustrates the opening and
closing of two files, one for input and one for output, as well as the
reading and writing of strings using fgets() and fputs().
In the example, pay particular attention to the second argument to the
fopen(). It describes the "mode" in which the file is intended to be
used. This mode includes some combination of the characters "r", "w", "a",
and "+". An "r" means "allow reading", whereas a "w" means "allow writing".
An "a" is short for "append". In other words an that you'll be writing, but
want to pick up at the end of the file -- and don't want to be allowed to
overwrite any portion of the file once it is written. This can be used,
for example, for logging.
As you use a file, the operating system keeps track of your
current position, sometimes known as the offset into the file.
As you might imagine, when a file is opened for reading, it is normally
set up so that you begin reading form the beginning of the file and
work down the file as you read. By contrast, when a file is opened for
appending, it i set up so that the offset is at the end of the file.
If a file is opened for writing, it is assumed that you'll be
overwriting data, so the file offset is set to the beginning of the file
and the file, if it already exists, is truncated.
If a "+" is present, the file is opened for reading and writing. The only
difference between an "r+" and a "w+" is that a "w+", like a "w" will
create the file if it doesn't already exist and a "r+" will not. An "a+'
is a weird mode where the file will be created if it doesn't already exist,
and the offset is set to the end of the file, and writes always occur at
the end of the file -- but reads can occur anywhere.
I've seen files opened "rw", and it seems to do the right thing. But,
in a technical sense, it does leave open the questions "Should the initial
offset be 0 or the end of the file?" and, "Is 'wr' any different?"
Perhaps the Right Thing is to use one of the canonical, and more descriptive
modes, eh? For example, "r+" or "w+".
Now, let's take a look at the first part of the example:
#include <stdio.h>
int main() {
FILE *fpi;
FILE *fpo;
char data[256];
fpi = fopen ("input.txt", "r");
fpo = fopen ("output.txt", "w");
...
}
fgets() reads a string from a file. It uses a line-oriented model
and tries to read an entire line from a file into one string, blank
spaces and all. It accepts not only a poiner to the sttring character
array, but also the size of the array, so that it can avoid overflowing
the array if the line is too long for the space provided.
Since fgets() does nothing to eliminate the newline characters that
normally terminate lines, the last character of the string is usually a
newline "\n". But there are two cases where this isn't be the case:
- If it is the last "line" of the file -- and there is no newline,
so it his the end-of-file (EOF) without hitting a newline
- The line is too long for the buffer that is supplied. In this case,
it'll read as much of it as it can -- while still allowing space
to store the terminating NULL character. The rest of the line,
the part that couldn't be read, including any newline a the end,
remains available should another gets() be called.
futs() writes a string to a file. It does not add a newline. So, if you
want a newline -- append it to the end of the string before writing or
with a subsequent fputs(), or the like.
So, let's take a look at the rest of the example:
#include <stdio.h>
#include <ctype.h>
int main() {
FILE *fpi;
FILE *fpo;
char data[256];
/* Open the files */
fpi = fopen ("input.txt", "r");
fpo = fopen ("output.txt", "w");
/* Read a line from the input file */
fgets (data, 256, fpi);
/* Remove the newline by replacing it with a null-character
/* It is worth noting that there is allready a null-character
* after the newline, but replacing the newline with another
* null-character cuts the string one spot shorter.
*/
data[strlen(data)-1] = '\0';
/* Write the string, less the newline to the output file */
fputs (data, fpo);
/* close both files */
fclose (fpi);
fclose (fpo);
return 0;
}
fprintf() and fscanf()
fprintf() works just like printf(), but the output goes to a file.
fscanf() reads input, as does fgets(), but it parses the input
and tries to match it against a format string provided. A scanf()
format string uses the same notation as a printf() format string,
which you'll recall from AWK. We're not going to go into tremendous
detail. Please type "man scanf" or "man 3 scanf" from a terminal
window or console for more details.
One important thing to note is that scanf() takes the ADDRESS of the
variable, not the variable itself. This should make sense if you think
back to our swap example -- it actually needs to change the variable's
value. But, also recal that arrays, by nature, are addresses, so the
&-address-operator is defined to do nothing and is, as a consequence,
unnecessary.
Important note: Forgetting the &-ampersand before arguments to
fscanf() is a very common and very dangerous error. fscanf() will
assume whatever variable happens to be passed in contains an address --
and will try to write to that address. If it isn't writable a SEGV or BUS
error will occur. If it is writeable -- corruption will occur!
Here's a really quick example:
#include <stdio.h>
#include <ctype.h>
int main() {
FILE *fpi;
FILE *fpo;
int number1, number2, number3;
char word1[256];
char word2[256];
char word3[256];
char words[3][256];
/* Open the files */
fpi = fopen ("input.txt", "r");
fpo = fopen ("output.txt", "w");
/* Read three words from the input file */
fscanf (fpi, "%s %s %s\n", word1, word2, word3);
/* Another example using an array */
fscanf (fpi, "%s %s %s\n", words[0], words[1], words[2]);
/* Read three ints (%i, int, or %d, decimal number) from the input file */
fscanf (fpi, "%d %d %d\n", &number1, &number2, &number3);
/* Write 'Hi Mom!' to a file */
fprintf (fpo, "%s\n", "Hi Mom");
/* Close both files */
fclose (fpi);
fclose (fpo);
return 0;
}
About stdin, stdout, and stderr
Each C program automatically has three file handles open for it: stdin,
stdout and stderr. The handle "stdin" is ties to the
"keyboard" and "stdout" is ties to the screen. The other one, "stderr" is
usually also tied to the screen, but can be tied to anotehr device, such
as a printer, log file, or error console.
Think about printf(). It is nothign more than an fprintf() where the file
handle is "stdout". The following are equivalent:
printf ("Hi mom!\n");
fprintf (stdout, "Hi mom!\n");
So, you shouldn't be surprised that there also exists a scanf(), and that
it is equivalent to a fscanf() on stdin. By exmaple, the following are
equivalent:
scanf ("%f", &floatNumber);
fscanf (stdin, "%f", &floatNumber);
There are, as it turns out puts() and gets() functions, but they differ
slightly from fputs() and fgets(), as follows:
- puts() automatically adds a trailing newline ('\n'), whereas fputs()
does not.
- gets() should never be used, fgets (stdin, ...) should always be
used instead. gets() does not limit the size of the string read
to the size of the buffer passed in. And, since the program can't
know in advance how much a user might type (or paste in), this is
inherently unsafe.