Return to lecture notes index
November 29, 2007(Lecture 20)
Example Source
The Not Especially System Call Lab
This week's lab is, in some sections, known as the "System Call Lab".
You'll notice that I've renamed it "The Mini-UNIX Shell". I also toyed
with the name "The Process Lab". So, what's in a name?
Well, the lab does make use of system calls. The library calls
that are new to this lab such as, fork(), wait(), and waitpid() have
system calls underneath the hood, to be sure. But, this is not new.
We've used system calls before. Any time we've made use of, for example,
I/O, the C library has made use of system calls to get the job done.
Who's In Charge Here, Anyway
So, what is a system call, anyway? Well, to answer that question,
we need to first take a better look at the operating system. Most
people operate under the assumption that the operating system is
something akin to air traffic control or a paramilitary police force.
The idea is that the operating system controls everything that is
going on, that it controls who gets what and when, and that it can
kill any process that is offensive.
And, this model is useful in that it does offer an explanation for
a lot of what we see when we look casually at our computers and their
operating systems. But, it does fail a more careful look. You guys have
written a machine simulator. You know the basic life of a processor --
they just charge through memory and execute instructions. So, when
the processor is in the context of a particular process chewing along
following the instructions of that program, where is the operating
system, this great controlling ruler, running? Answer: It is not.
If the processor is running a user program, it is not simultaneously
running the operating system. Yep, you got that right. Barring anything
else, a program can run forever, starving the operating system, itself,
from getting to the processor.
The Timer and Interrupts
Well, obviously that system won't do. It doesn't explain reality -- that
the OS does seem to be in charge. Here's how the game is played. There is
a piece of hardware known as the timer. At periodic intervals,
this timer counts doen to zero and interrupts the processor.
It pokes the processor directly, or via some arbitration hardware, and
let's it know that it time to let the operating system run again.
The processor makes the operating system run again via what is, in
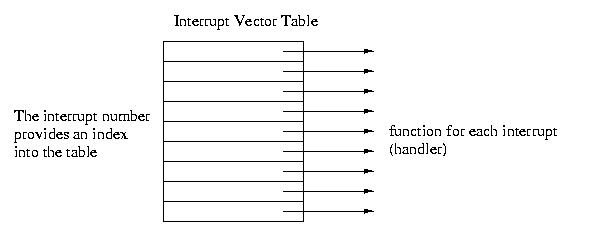
effect, an array of function pointers known as the Interrupt Vector
Table (IVT). Every device on the system has a handler, a function
that services it. These handlers are known as Interrupt Service
Routines (ISRs). Each interrupt has a number, for example 0 for the
timer. When the hardware device wants attention, it uses its wire to
signal the processor. The processor then executes the appropriate
function fron the IVT.
So, if we ask the disk to get some data for us, when that data is ready,
it can signal the processor, which will then run the disk's ISR to
copy the data. When data shows up on the network, the network adapter
can signal the processor via its own ISR. This mechanism is also used
for the processor to signal the operating system that there is a
problem with the process that is currently running, for example
a divide-by-zero or an attempt to make an invalid memory access.
This type of situation often results in the OS ending the current
process as you have seen with SIGSEGV.
Regardless, periodically, the timer will signal the processor that
"time is up" for the current processes. When this timer interrupt goes off,
the processor runs the timer handler, which is in-effect a part of the
operating system's scheduler. The OS can then look around and decide if
that process should continue running or if it should take a break to
allow another process to run for a while.
This interrupt system enables the operating system to schedule multiple
processes to take turns so quickly that they all seem to be running at
the same time. So, for example, your web page can update at the same
time that you type an email and move the mouse.
How does all of this get set up, you ask? When a computer starts up,
it goes throug ha boots strap process. The boot sector
is read off of the disk. This boot sector contains the instructions
about how to initialize, a.k.a. boot strap, the operating system.
Part of this process is initializing the IVT and storing its address in
a register so that the processor can find it. Another part of it is
telling the timer how often to interrupt the processor.
Protection, Supervisor Mode and Interrupts
Well, as fun a story as this is, what does it have to do with
so-called system calls? Well, a little more background first. A quick
story about protection, to be specific. If a process, in effect, owns
the processor while it is running, what prevents it from reading another
process's memory? The OS's memory? Or from accessing a file on disk that
contains a user's private information?
The hardware limits the access to hardware devices as well as to certain
parts of memory that are specially tagged so that user processes can't,
under normal circumstances, access them. So, for example, a process
is normally not able to access the disk or to read protected memory.
Instead accessing these protected resources can only be done when in
a special mode often known as supervisor mode. And, there is
exactly one way to get into supervisor mode -- by executing one of
the functions via the IVT. In this way, supervisor mode can only be
entered in a very controlled way -- only through the functions that the
operating system, itself, set up in the IVT.
So, for example, when the disk needs attention, and the disk handler runs,
it can access the disk, the operating system's data structures, and
the destination process's memory, because it is running via an ISR. When
the function ends, privilege is lost.
And, again, I want to observe that the protected resources include not
only hardware things like the disk, the network, and memory, but also
more abstract resources, such as the data structures that represent
processes, communication channels, &c.
See how nice and pretty? We now see how the OS can periodically get back
in the saddle via the timer, as well as how it can gain access to
resources not normally accesible via ISRs.
So, What's a System Call, Anyway?
Enough already! What is a so-called system call? Well, we know
how the hardware can rquest's the OS's attention and invokes the OS's
special privileged functions via the ISRs. But, what happens when a
program wants to invoke the OS to do something that requires privilege,
such as request data from the network or the disk? Or to do something that
otherwise requries the OS, such as create a new process?
Well, for it to access the privileged resources, we know that it has to
go through the IVT -- if it doesn't it can't get into the special mode
needed to access the protected resources. And, this is exactly what it
does. There is a special instruction often knwon as TRAP. This
instruction causes the trap-handler to run from the IVT. This handler
looks on the stack for a single argument -- a number which indicates
what the user wants to do. This number, whcih is #defined to a
useful name, suhc as OPEN, CLOSE, READ, WRITE, &c is then fed to a big
switch statement which calls the appropriate function. But, since this
function is invoked via the ISR, it has privilege.
So, what is a so-called system call? It is a function that is invoked
indirectly via a TRAP instruction such that it passes through the IVT
and has privilege.
We've seen thing that are, at least traditionally, system calls:
read() and write(), for example. And, today we'll see some more, such
as fork(), wait(), waitpid(), and getpid(). No magic here. They are
just C library calls that, deep down inside, require privs.
Notice that I said, "at least traditionally". This is because the
so-called system call interface has evolved over the years and
is no longer the same as it once was -- and isn't the same across all
flavors of UNIX. But, the details there are really the domain of
15-410 -- not 15-123!
The Life Cycle of a Process
Okay. So. Now that we've got a better understanding of the role of the
OS and the nature of a system call, let's move in the direction of this
week's lab. It involves the management of processes. So, let's begin
that discussion by considering the lifecycle of a process:
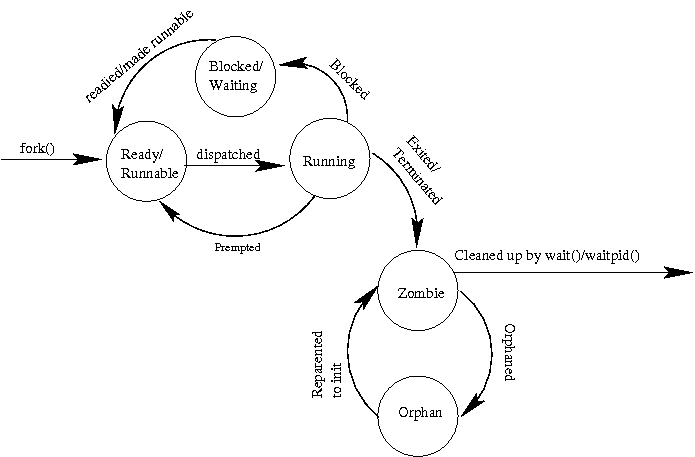
A newly created process is said to be ready or runnable.
It has everything it needs to run, but until the operating system's
schedule dispatches it onto a processor, it is just waiting.
So, it is put onto a list of runnable processes. Eventually, the OS
selects it, places it onto the processor, and it is actually
running.
If the timer interrupts its execution and the OS decides that it
is time for another process to run, the other process is said to
preempt it. The preempted process returns to the ready/runnable
list until it gets the opportunity to run again.
Sometimes, a running process asks the operating system to do
something that can take a long time, such as read from the disk
or the network. When that happens, the operating system doesn't
want to force the processor to idle while the process is waiting
for the slow action. Instead, it blocks the process.
It moves the proces to a wait list associated with the slow resource.
It then chooses another process from the ready/runnabel list to run.
Eventually, the resource, via an interrupt, will let the OS know that
the process can again be made ready to run. The OS will do what it
needs to do, and ready, a.k.a., amke runnable, the previosly blocked
process by moving it to the ready/runnable list.
Eventually a program may die. It might call exit under the programmer's
control, in which case it is said to exit or it might end
via some exception, in which case the more general term, terminated
might be more descriptive. When this happens, the process doesn't
immediately go away. Instead, it is said to be a zombie. The
process remains a zombie until its parent uses wait() or waitpid() to
collect its status -- and set it free.
If the parent died before the child, or if it died before waiting for
the child, the child becomes an orphan. Shoudl this happen, the
OS will reparent the orphan process to a special process called
init. Init, by convention, has pid 1, and is used at boot time
to start up other processes. But, it also has the special role of
waiting() for all of the orphans that are reparented to it. In this
way, all processes can eventually be cleaned up. When a process is
set free by a wait()/waitpid(), it is said to be reaped.
fork()
In order to create a process, we make use of the fork() call. Tradionally,
for is, itself, a system call. These days, the actual system call may, or
may not be a fork(). But, this isn't important. What is important is
that when a process calls fork(), it creates a nearly exact clone of
itself. One process goes into the phone booth -- and two step out.
The original process is known as the parent process. The
new one is known as the child. The parent and the child are
virtually alike. For our purposes, there are only two differences.
The first difference is that they have differnt process ids (pids).
A pid is just a number that the OS uses to identify a process. The second
difference is that fork() returns a 0 to the child, but returns the
pid of the child to the parent. This is convenient, because it allows
the program, now running in two differnt processes, to do different
things in each of the two processes.
The Exec Family
For example, it is not uncommon to want the child process to assume
some other identity -- to, in effect, become a different program.
this is done with one of the exec calls (man execve, execvl, execvp, &c).
What an exec call does is to load, from disk, a new process image
into the current process. So, the current process's memory is dumped
and the new process's image is loaded into memory from its executible file.
Take careful note, when an exec function is called, in the normal case,
it doesn't return. This is beause the process has assumed a new identity
-- the exec is gone. Most ofen, an exec faisl becuase the path to the
executible is wrong and the executible can't be found.
The "l" versions of the functions, execl() and execlp() take the arguments
in a long list, each of the new programs' arguments are passed separately
as arguments to exec. It is very important to note that the last argument
to exec() and execl() must be a NULL pointer -- otherwise, since it
doesn't know how many arguments there are, when walking down the stack, it
doesn't know when to stop.
The "v" version of the fucntions, execv() and execvp(), take the arguments
in an array, mcuh like main gets its arguments via the argv[] array. Again,
since the array has no length, it is important that the last entry be a
NULL.
The "p" version of the functions, execvp() and execlp() will search the
path for a matching executible, as compared to execv() and execl(), where
the full path, e.g., /bin/ls, must be specified.
Lastly, the 0th argument should be the name of the program, not a
"real" command-line argument. It doesn't have to match the executible
name -- but normally does. It is passed in as argv[0] to the new
program's main().
So, basically, the argv[] array that is passed into execl(), execlp(), &c,
is the same as the argv[] array as you are accustomed to receiving within
main(). execl() and execlp() take the same list of arguments, including
the 0th and terminating NULL -- but take them flattened out, with each
being passed as a separate argument to exec.
To really understand this, you'll need to read the man page, look
at our example, and search the Web for another example or two.
wait() and waitpid()
The two function calls wait() and waitpid() are normally used to wait for
a process to end. So, consider a UNIX shell. When you start up "vi" or
"emacs", your shell waits until the editor eds before producing a new
prompt. The shell waits by calling wait() or waitpid().
In either case, the wait call will block until the child process is done.
Once the child is done, the wait call will return. By waiting for a child
in this way, the parent also reaps the child. As we discussed earlier,
the child will remain a zombie until reaped by a wait.
The wait calls give the caller back an integer that contains some information
about the child's state. We're not going to worry about it here. Either
pass in a pointer to a real interger, or a NULL. But, if you are curious,
do a "man 2 wait". Notice the macros, such as WIFEXITED() that can be used
to decode this status.
The wait() call will wait for any child. If it is desirable to wait for a
particular child, the waitpid() call can be used. It will only wait for
the child who's pid is specified. waitpid() can be made to wait for any
child by passing in a pid of 0 or -1. Upon success, both forms of wait
return the pid of the child they reaped.
waitpid() also has another argument that will become important for this
lab -- the flags. If a flag of WNOHANG is specified, wait will not
actually block. If there is an available zombie, it will collect its
information and return its PID. If no child is currently available, the
WNOHANG glag prefents wait from blocking. Instead, it will return -1
if there are no more children, or 0 if there are children -- but none
are zombies.
A Quick Example
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <errno.h>
#include <unistd.h>
#include <stdlib.h>
int main() {
int status;
int pid;
char *prog_argv[4];
/*
* Build argument list
*/
/* Remove the path or make the path correct for your system, as needed */
prog_argv[0] = "/usr/local/bin/ls";
prog_argv[1] = "-l";
prog_argv[2] = "/";
prog_argv[3] = NULL;
/*
* Create a process space for the ls
*/
if ((pid=fork()) < 0)
{
perror ("Fork failed");
exit(errno);
}
if (!pid)
{
/* This is the child, so execute the ls */
execvp (prog_argv[0], prog_argv);
}
if (pid)
{
/*
* We're in the parent; let's wait for the child to finish
*/
waitpid (pid, &status, 0);
}
return 0;
}
This Week's Lab
This week's lab asks you to build a rudimentary UNIX shell. It is basically
one big work loop. At the beginning, you emit a prompt. Next, you read a
line from the user. Then, much like the assembler, you parse this line to
figure out the name of the command and its arguments. You also note if the
last thing on the line is an &-ampersand. If it is, this is dropped
because it isn't an argument -- but you note that the command is to be
run in the "background".
For a typical forground command, you'll fork() the command, waitpid()
for it, then loop back to the top and do it all over again: prompt,
read, parse, exec, ...
A "background" command is, at some level, simply one for which you won't
do a blocking wait. Instead, you'll immediately loop back to the top,
emit a prompt, &c. But, this simply change can actually throw a wrench
into the works.
First notice that I asked you to use a waitpid(), not a wait() to wait
for a foreground process. This is critical. Imagine that you launch
a background process. Then, you loop around and launch a foreground
process. While you are waiting for the foreground process to end -- the
background process ends. If you use a wait(), rather than a waitpid(),
you'll be fooled. You'll thnk you just waited for the foreground process,
stop waiting for it, and go back to the top of the loop. By using waitpid()
and waiting exactly for the child process that you started with the intention
of keeping it in the foreground, you can make sure that you aren't fooled.
But, what about those background processes? We do need to wait for them,
or when they are done, they'll stay zombies until out shell finishes.
Well, that's where the WNOHANG flag comes in. Periodically, we need to
check for zombie background jobs. So, we do this at the top of the loop
before emiting the prompt.
We call waitpid(), btu pass it a 0-pid, so it'll wait for anything. And,
we give it the flag WNOWAIT, so it won't hang if there are no zombies.
We then wrap it in a loop. As long as it returns a valid PID, a number
greater than 0, we call it again -- it is reaping zombies. But, when
it returns a 0 or a -1, we know that it wasn't able to reap a zombie
without waiting -- so ti is done for now. We cleaned up the zombies of
the background processes, so we can no emit the prompt and carry on.
So, now we see the whole of the work loop:
- Clean up zombies using a loop around waitpid(0, NULL, WNOHANG) or
waitpid(-1, NULL, WNOHANG)
- We emit our prompt
- We read the user's input, probably using fgets()
- We parse it, probably using strotok(), but maybe by using sscanf().
- We fork to create a new process
- The child exec's the new program with the right arguments
- If it was to be a foreground process, the parent does a waitpid(),
waiting specifically for the recently forked child. If not, the
parent can just continue
- The parent loops back to the top and does it again
The only remaining details are that "exit" is special -- it should cause
the shell to call "exit()" rather than run a program. The second is that
you should use a data structure, such as your generic linked list, to
keep track of the commands that you run. They should be added to the list
before being forked and removed when wait()/waitpid() reaps them. And, the
"jobs" command should show this list of jobs.
Please see the handout for the details of the lab's requirements.
Today's lecture was intended to give you a quick glance at how to get
the job done -- not the requirements of the lab in detail.