Return to lecture notes index
January 14, 2009 (Lecture 2)
Compilation, Execution, and the JVM
The first step in the process is to "compile" the program. This
means to translate the Java code into a highly specialized set of
instructions that actually direct the computer hardware.
In many languages, this compialtion process produces an executible
program that runs on the actual hardware. The problem with this
approach is that each program must be recompiled for each platform.
For example, the smae C++ program would need to be compiled separately
for each of PC, Sun, SGI, and Mac computers. This makes the software
more complex to deploy and maintain.
Java uses a virtual machine, known as the Java Virtual
Machine (JVM). Basically, Sun defined a hardware system and then
wrote a program to simulate it. This single program is compiled for
each supported architecture. Then, Java programs are compiled for the
JVM. As a result, any compiled Java program can run on any JVM --
regardless of the actual, physical host hardware. This is said to
be a "compile once run anywhere" system.
So, when you run "javac SomeClass.java", it compiles the Java code to
machine code for the JVM. Java calls this machine code the byte
code. When you run, "java SomeClass", you are starting ther JVM
program and asking it to start the static main() method of the class
SomeClass, defined within the file SomeClass.class.
static methods, sometimes known as class methods aren't
actually behaviors of instantiated objects. Instead, they are just
"things to do" that live within the name space of the class.
Primitives versus Objects
Let's begin by considering one very important question. In truth, it is one
that is sometimes on the minds of intro students -- even at the end of the
semester:
I have an idea about what is and what isn't an object, and what is and
what isn't a primitive, but I really don't know exactly what the difference
is. What is it?
Primitive variables are simply named storage areas. And, in Java,
typed, named storage. We can identify a particular storage area using
a variable name and, using this name, we can read and write a value.
Since the storage is typed, the storage area can only hold one type of
value. If we try to read or write a different type of value, the
compiler will stop us.
Objects are a more sophisticated language construct. Object are
complex types that are composed of one or more values, known as
member fields (instance and class variables) and
behavior definitions (methods).
You may have, in a prior course, discussed Abstract Data Types
(ADTs). Abstract data types are models that include both the
data, itself, and the ways that the data can be used or manipulated.
For example, we might use the array data structure to store collections
of all sorts of different things: business cards, an hourly planner,
or the pages of an event log . It might make sense to linearly search the
array for all three applications. But, not everything that applies to one
applies to another.
I really wish I could insert new hours between old ones, just as I can
stick new business cards into the middle of a Roladex. But, unfortunately,
the world doesn't work this way. There's only one hour between 2:00PM
and 3:00PM on any given day. It makes sense to insert buiness cards, but
not hours. Similarly, it might make sense to add pages to the end of
an event log -- but I can't add hours to the end of a day. No matter
how hard I try, there are only 24 of them.
If we build a library of array operations, such as search insert-in-middle,
insert-at-and, &c, and then use this library for each of these applications,
it will work -- but we run the risk of making mistakes. There is nothing
that prevents the creation of the 36 hour day, except correct programming.
But, if we have a way of binding the right operations to the right
data in software, we can avoid these mistakes. The insert method
associated with business cards won't be available for the hourly
planner.
Classes give us a way of doing this. They allow us, the language
to enforce the properties of our abstract data types by binding
the operations and the data together to give us a complete
blueprint for some type of object -- while isolating these things
from the properties and behaviors of all other classes of objects.
So, to answer the original question, primitives are just typed
places to store and retrieve information. Objects are
complete models of components of a system that completely contain
the attributes and behaviors of the objects. Objects both include
their own attributes and behaviors, and exclude others.
The Age Old Question: What Is "Person p;"?
Assume that we've got some class, Person:
class Person
{
// Full definition
}
Consider the following declaration:
Person p;
What is "p"? About half of the class answered, "A Person". Well, not
exactly.
If we were programming in C++, that answer would be correct. "p"
would be the name of the variable that contains the members methods
and fields of the Person class. In other words, "p would be a Person."
But, in Java, "p" is not a Person. Instead, it is a primitive. Specifically,
it is a reference variable. A reference is nothing
more than a name for an object -- a way of "referring to an object".
In Java, references are the handle we use to manipulate objects. If we
want to interact with an object, we do so by using its name. Remember
that, at this point in lecture, I started calling people by name and
asking them to do things. This is exactly the way Java works.
"p.walk()" sends the walk message to the object whose name (reference)
is stored in the variable "p" in exactly the same way that "Dom, please
stand up" send the message to Dom to stand up.
In Java, we manipulate objects using their names, which are called
references. These variables, which hold references, are known as
reference variables.
When we use the "new" operator to create a new object, it returns
a name for the new object. This name, a reference, is stored in
a reference variable (or the "new" is pretty useless).
Person p = new Person();
What is a reference, Anyway?
While we're in the process of looking at the machinery, memory, and
memory addresses, what is a reference? No, really, what is it?
Every object in memory is known by its address in memory.
Ultimately, a computer needs to use the address to look the object
up in memory. There exists a mapping, known as the symbol table, from
symbols, such as variable and methods, to their actual address. This
is how the computer can use your choice of variable names to find objects.
It just looks them up, finds the address, and asks the hardware to get the
object via the address.
In C and C++, programmers can directly access, and even manipulate,
addresses. But, in Java, there is an extra level of indirection. Java
maintains a one dimensional array knwon as the reference table. Each
time a "new" object is created, Java searches this table for an
empty entry. It then records the address in the empty slot and hands
back the index of this slot.
This index, an integer, is the reference. Although the semantics of
Java don't let you see the number -- it is there. As a result,
a reference is a primitive -- it is the thing that it
identifies that is a first-class object.
-------------
0 | address |
|-------------|
1 | address |
|-------------|
2 | address |
|-------------|
3 | |
|-------------|
ref=4---> 4 | address |
|-------------|
5 | |
|-------------|
6 | address |
|-------------|
... | ... |
-------------
By hiding the address of objects in memory from the programmer, Java
becomes safer and more flexible. Programemrs can't wrtie directly
into meory or place objects on top of each other -- they can't play
directly with memory addresses or memory by address. And, because
the program does not have access to the memory address, Java can move
the object in memory, so long as it updates the reference table with the
new address. The program will look up the same reference, looking at the
same slot, but will get a different memory location. This could be useful,
for example, if the garbage collector wanted to do compaction. Compaction
is the process of moving objects around in memory to pack them tightly in
order to coalesce the small scattered slivers of free meory between objects
together, after the allocated objects. This makes it more available for
reuse, because it is big enough to satisfy larger requests.
Identity Is Not Necessarily Equality
In Java, as with many other languages, we can check to see if
two primitives are the same by using the "==" operator. But, in
Java, I am going to refer to this as the "identity" operator.
It doesn't ask the question, "Are these two things equal?" Instead,
it asks the question, "Are these the same thing?"
If two variables name the same thing, then the thing names by both
is obviously eual to itself. So, when we are playing with primitives,
identity and equality are exactly the same thing.
But, when we shift our focus to objects, they can become two different
things. We use the "==" operator to test for equal identity, and the
".equals()" method to test for equality.
"==" evaluates to true if, and only if, the references on both sides
name the same object. For example, two different $1 bills are not
the same dollar bill -- even though their value is equal.
All objects have a .equals() method. If it is properly defined, it is
used to compare the value of objects:
paperMoney bill1;
paperMoney bill2;
if (bill1.equals(bill2))
System.out.prinln ("Both bills have the same value");
if (bill1 == bill2)
System.out.prinln ("bill1 and bill2 are exactly the same piece of cloth.");
Although the .equals() method is automatically defined on all objects,
it almost always has to be redefined for each class. The default comparison
is pretty brain-dead. So, the implementor of the proverbial Person class
should implement a .equals() method that is able to meaningfully
determine if two people are equal -- a pretty cool job for a mortal, if you
ask me.
We'll talk more about the .equals() method shortly. In particular,
we'll discuss the mechanism by which Java ensures that it is present
in all objects.
The String Example
Java's String class makes for a great example of the distinction.
In lecture, I actually used this example to motivate the equality
versus identity discussion above -- but it makes more sense to reverse
it in the lecture notes.
Remember that in Java, unlike other languages such as C,
Strings are first class objects. By comparison, what C programmers
call a string is nothing more than an array of characters. C++ has
String object. But, unlike C++, Java's strings are immutable.
Once created, they cannot change.
Instead, we just create new ones and allow the garbage collector to recycle
the old ones. This is because not all edits upon stirngs are "in place" --
some, for example concat(...), would require the size of the string's
internal memory to grow to accomodate a longer string. As you'll learn in
15-213, it isn't generally possible to grow a memory allocaiton -- instead,
one usually needs to get a new, bigger allocation and copy the old data into
it.
Regardless, take a look at this code fragment and predict its output:
String s1 = new String ("Surprise!");
String s2 = new String ("Surprise!");
if (s1 == s2)
System.out.println ("The two strings are the same.");
else
System.out.println ("The two strings are different.");
When I polled the class, about 2/3 of the class got this right. No doubt
the number was so high simply because the example would have been boring
otherwise. It prints, "The two strings are different."
But, after our discussion about "==" vs ".equal", this should make sense.
The version that does the more intuitive comparison follows:
String s1 = new String ("Surprise!");
String s2 = new String ("Surprise!");
if (s1.equals(s2))
System.out.println ("The two strings are the equal.");
else
System.out.println ("The two strings are not equal.");
This prints, as everyone understood, "The two strings are equal".
String Methods
Just to refresh your memory, below are some frequently used String methods:
- s1.concat(str s2) - return a new string that is like s2
with s1 appended to the end.
- s1.toUpperCase() - return a new String that is like s1, except
entirely in uppercase.
- s1.toLowerCase() - return a new String that is like s1, except
entirely in lowercase.
- s1.length() - returns a primitive int telling you the length of the
String
- s1.trim() - returns a new String, exaclty like s1, absent any
leading white space.
- s1.substring(int beginIndex) - returns a String like s1,
absent any characters before index beginIndex.
- s1.substring(int beginIndex, int endIndex) -- as above,
except it also leaves off characters after index endIndex.
A Careful Look at Mutation, or More-Precisely, the Lack Thereof
Recall that one important characteristic of Strings is that they are
immutable -- once born, a String can never change. When one invokes
a seemingly-mutator method upon a String, the original object
does not change. Instead, a new String is created with the new
value and the original object is left intact. Sometimes we miss this
subtlty in a casual read of the code, because we often assign a
reference to the new object to the reference variable that was previously
associated with the old one. In the common case, this leaves the old
object unreferenced and able to be garbage collected. The following
example illustrates this idiom:
String s1 = "Hello";
String s2 = " world";
s1 = s1.concat(s2);
But, if we structure our code a little differently, we cna find the
original, unchanged object. We do this by aliasing it:
String s1 = "Hello";
String s1prime = s1;
String s2 = " world";
s1 = s1.concat(s2);
System.out.println (s1); // "Hello world"
System.out.println (s1prime); // "Hello"
The designers of Java probably made made Java strings immutable for two
reasons a) to avoid hiding the fact that the edits aren't necessarily
in-place, and b) becuase it prevents what might be unintended side-effects
in the case of the mutation of an aliased string. Given the symantics as
they exist with Strings, one can only change the string visible via some
reference by re-assigning that reference.
StringBuffer
StringBuffers, unlike Strings, are changeable. If it is
possible to do the requested edit in-place, it happens in place. If not,
the storage is ransparently reallocated. Neither the program, nor the
programmer ever need to become aware of the details of the storage.
But, it is important to realize that StringBuffers and Strings
do have slightly different semantics. Since StringBuffers appear to
be edited in-place, if there are multiple references aliasing the same
StringBuffer, and the StringBuffer is changed, it will
appear mutated via any of the references. Unlike the example for
an immutible String, which was duplicated rather than edited-in-place,
in this case each reference identifies exactly the same object.
Let's consider our earlier code example, but this time with
StringBuffers:
StringBuffer sb1 = new StringBuffer("Hello");
StringBuffer sb1prime = s1;
StringBuffer sb2 = new StringBuffer(" world");
sb1 = sb1.append(s2);
System.out.println (sb1); // "Hello world"
System.out.println (sb1prime); // "Hello world"
StringBuffers have a rich set of methods, not unlike those
associated with Strings. You can find a list in the
StringBuffer API Docs. But, keep in mind that
they are different, unassignable types. One cannot assign a
StringBuffer to a String or vice-versa. And, this is true for
literals as well. The following line of code, though intuitive, will result
in a compile-time error:
StringBuffer sb = "Hello World"; // SYNTAX ERROR: incompatible types
Java Input/Output (IO)
Today we covered Java Input/Output. Our main tool for this was a Java a
Java class called a Scanner. You can find the official Java Documentation
for Scanner
here .
First, let's take a look at some example code and see what it does:
// Scroll to the bottom of the lecture notes for information on this
import java.util.*;
import java.io.*;
class Input {
public static void main (String[] args) {
// Here we declare a new Scanner called keyboard
Scanner keyboard;
// Here we define keyboard to be a scanner dependent on user input.
keyboard = new Scanner(System.in);
// Declares a new String named input and sets it equal to "continue"
String input = "continue";
// This is a while loop which we'll look at more in a class or two
// Basically it will run and rerun the code inside the loop until the
// condition !input.equals("Q") is false!input.equals("Q") will become
// false when the user inputs Q
while (!input.equals ("Q")) {
//We set the String s equal to the line of input entered by the user.
//We have to use (String) because it is possible that keyboard.next()
//to return something that is not a string
input = (String) keyboard.next();
// We print out the new String s
System.out.println(input);
// Goes back to While loop and checks to see if condition is true.
// If true, it will run these two lines of code again.
}
// This lets you know when the while loop is exited
// and is just for example purposes
System.out.println("We left the while loop");
}
}
If we run this code, we will be prompted to type in our user input. Then the
while loop will run keyboard.next() and get the next token, using the
default delimiter of " ", a.k.a. a space.
For example, the code above looks for our delimiters (spaces) and prints out
the tokens before each delimiter.
If given the input, "An example sentence". It should print out:
An
example
sentence
After printing out, as above, it again prompts the user and prompts for
more input, until a 'Q' is entered. For example if we input:
A B C Q
It should print out:
A
B
C
Q
We left the while loop
Adder
Here's another example, this time looking for integers.
import java.util.*;
import java.io.*;
class Input {
public static void main (String[] args) {
int total = 0;
int i = 0;
Scanner keyboard;
keyboard = new Scanner(System.in);
//This time, the while loop is exited when the integer i is less than 0
while (i >= 0) {
//sets integer i to the next integer in the input line
i = keyboard.nextInt();
//adds i to total and sets it equal to total
total = total + i; // total += i;
//prints out total
System.out.println(total);
}
System.out.println("We exited the while loop");
}
}
The only new information in this one should be the use of .nextInt() which
gets the next integer, rather than the next string.
Let's take a look at example inputs and outputs for this one. If we provide
"1 2 3" as input, it should print out:
1
3
6
If we provide an additional number as input, "10", it will print out:
16
Then, if we provide it a "-1" as input, it will terminate:
15
We exited the while loop
Note that it performed the rest of the lines of code inside the while loop
before leaving, because it only checks the condition when you get to the end
of the loop.
Reading From a File
This time let's try it with a file input, rather than a user input (System.in)
import java.util.*;
import java.io.*;
class Input {
// Don't worry about the throws exception for now, just remember to type it
// in there whenever you're dealing with Input/Output
public static void main (String[] args) throws Exception {
int total = 0;
int i = 0;
Scanner file;
//this will open the file (in the same directory as the program)
// named input.txt and use that instead of user input
file = new Scanner(new File ("input.txt"));
//.hastNext() checks to see if there is another token
// in the file and returns a boolean value. Since we are
// dealing with a file here, we can use .hasNext() because the scanner can
// tell when the file ends whereas with System.in, only the user knows when
// they are going to stop sending in inputs
while (file.hasNext()) {
i = file.nextInt();
total = total + i; // total += i;
}
System.out.println (total);
}
}
If the input file is as follows...
1 2 3
12
10
1 7
...it should print out:
36
Useful Tidbits
The default delimiter for Scanner class is a space, " ".
The hasNextXXXXX() methods only works for files, you cannot use them with
System.in. In the case of files, the input is limited to what is contained
within the file. But, in the case of System.in, the user can provide
additional input at any time.
You can fake an "end of file" from the keyboard by typing "Ctrl + d"
If you request a specific type of input, e.g. an "int" via nextInt(),
you will not get the carriage-return that makrs the end of the line --
it isn't part of the int. You'll need to clean it out with a subsequent
next() or nextLine().
Exceptional Control Flow
Let's think about the normal process involved when two object communicate.
One object sends another object a message. That occurs by a method
invocation. Then, after exhibiting some behavior, the receiving object
replies. It does that by returning from the method call, and possibly by
returning a value.
But, what happens when something out of the ordinary happens? For example,
what happens if the method encounters an error and can't perform the
requested actions? In C or Pascal, this is typically handled by using
some special return value.
For example, in C, the convention is that all functions return "int"
values. A return value of 0 indicates that the function completed
successfully. Each negative return value generally indicates a different
error. And, each positive return value generally indicates a non-error
condition that prevented the function from completing. Since the
return values are used to indicated the return type, values that are
returned are generally managed as parameter's using C's "pass by address"
mechanism.
But, this type of undocumented hackery is not necessary in C++ or Java.
These languages support an "exception mechanism" that can be used to
handle errors and other exception conditions -- both within a message
and to communicate unhandled errors up the call chain.
As you'll learn today, Java's exception mechanism is far superior to the
approach used by C, Pascal, and others. It can be used to remove error
handling from the body of code, making the algorithmic component
much cleaner. It is also much more self-documenting, because each type
of error is represented by a meaningfully named class, not by a number.
And, since it provides a different mechanism for returning in the
exceptional case than the normal case, return values can be just that.
All in all, it makes code more logical and more readable.
Representing an Error (Or Other Exceptional Condition)
In Java, errors or other exceptional conditions are represented with
instances of the Exception class. An Exception is a reasonably
simple class. For our purposes it has a two constructors, one of which
take as String message, and one of which is the default constructor,
which takes no parameters.
When an exception event, a.k.a, exception, occurs, the code that detects
it creates a new Exception to represent the problem. When calling the
constructor, it generally sets detailed information about the situation
in plain-language, by passing it as the "message" to the constructor.
When an Exception is converted to a String using toString(), it is
this message that becomes part of the returned String.
Types of Exceptions
As we discussed moments ago, when errors or conditions were returned from
C or Pascal functions, this return often took the form of a negative return
value, with a different return value for each condition. The calling
function would simply use a collection of if statements, or a switch/case
statement to demultiplex the error conditions and take appropriate action
to sort out the return value and take appropriate action. But, so far,
in Java, we've only discussed one type of Exception. How are different
conditions represented?
Java represents different types of Exceptions using inheritence. In Java,
the generic Exception class can be extended to form different types of
Exceptions. In fact, even the derived types are often extended to create
even more specific types of exceptions.
Just to show an example, here is a very small piece of the
Exception inheritence tree:
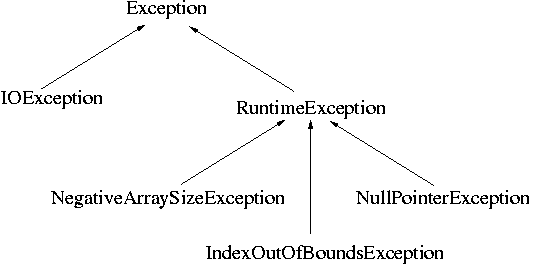
Creating Your Own Exceptions
You can create your own Exceptions, just by extending the Exception class.
Let's consider a situation where we ask the user to enter a number between
one and ten, inclusive. If the user enters a number outside of this range,
we might want to throw a OutOfRangeException.
class OutOfRangeException extends Exception {
public OutOfRangeException (String message) {
super (message);
}
}
You probably haven't seen it before, but "super()" invokes the constructor
of the super, a.k.a., parent class. In other words, the constructor for
OutOfRangeException will take a message as a String parameter and pass it to
the constructor of the Exception class. Our function is now an Exception
and handles a message exactly as does the generic type -- but, since we
have a new type of extension, we will be able to tell what type of
situation is present.
Throwing Exceptions
When we "throw" an exception, we activate Java's exception handling
facility. Throwing an exception is easy. We simply create the exception
and throw it, as shown below:
public static void verifyRangeInclusive (int lower, int upper, int candidate)
throws OutOfRangeException {
if ( (candidate < lower) || (candidate > upper))
throw new OutOfRangeException ("" + candidate +
" is outside of the range " +
lower + " - " + upper + ", inclusive.")
}
Notice the clause, "throws OutOfRangeException". Unless you specifically
use an exception that is of an "unreported" type, when a method can throw
an exception, it must be documented like this. If the method can throw more
than one, they are just listed, separated using commas.
Try and Catch
So we've learned how to throw new exceptions, but if we just throw the
exception, our program is going to crash because the exception isn't
handled. To be more precise, the exception will be thrown down the call
stack until it is thrown out of main(), at whcih time the exception
will be printed and the program will end.
So how do we go about actually handling the exception so that things don't
have to die? This is a two step process. First we identify the code that is
at risk for an exception using a "try block". Second, we "catch" or handle
any exceptions that happened to occur within the try block.
Each try block needs to be followed by at least one "catch". Each "catch"
catches a particular type of exception and is activated only in the event
that that particular type of exception arises. As a result, we might
need several different catch blocks to handle different types of exceptions.
A catch block is activated by an exception if (a) the exception is an
exact match or, (b) the exception is derived, directly or indirectly, from
the one associated with the catch block. For example, if the catch
block catches Exceptions, it will catch any type of Exception,
such as a NumberFormatException, or an OutOfRangeException.
Remember, this relationship is established by the "extends" clause in
the exception's definition.
Once we catch an exception, it is caught. It will not continue to travel.
So, if we catch an exception in one catch block, it will not be subsequently
caught by another catch block, either locally, or further along the
call chain. If we do want to allow an exception to be caught by a
catch block further down the call chain, we can "rethrow" it, by throwing
the exception within the catch block. Since the catch block, itself,
is not within the try block, it will be thrown further down the call chain,
not further down the list of catches associated with the same try block.
The example below catches both the InputMismatchException thrown
by the nextInt() method if the user enters a non-integer. It also catches
the OutOfBoundsException thrown by the verifyRange() method if
the user enters a number outside of the prescribed range.
try {
int intNumber = keyboard.nextInt();
verifyRangeInclusive (1, 10, intNumber);
System.out.println ("The number was: " + intNumber);
}
catch (InputMismatchException ime) {
System.out.println ("Not an int number");
ime.printStackTrace(); // Print the stack trace (see discussion under exception propogation)
}
catch (OutOfRangeException oore) {
System.out.println (oore.getMessage()); // Print the mesage
}
catch (Exception e) {
System.out.println ("Unexpected exception: " + e);
throw e; // Rethrow
}
Exception Propogation
We'll talk more about how methods are called in when we talk
about "recursion". But, for now let me observe that a compiler
needs to orchestrate not only the invocation of methods, but also
their return. In other words, when a method returns, it needs to
return to the same place that it was before it was called. This is
true for the first method that is called -- and for each subsequent
method that is called. It doesn't matter how many are called, each
one needs to return to exactly where it left off.
The upshot is that the compiler keeps a list, known as the call stack
of the methods that are called leading to the current method. When an
exception is thrown, it travels along the call stack, from one method
to its caller, until it is handled. If it is not handled by the time it
leaves main, the program ends and prints the list of methods that it
travelled along the stack.
The example below blows up because there is no string associated with
the variable "s". A NullPointerException is thrown when we try
to call the toUpperCase() method via a null reference. Notice
the call stack that is printed when it runs:
import java.io.*;
import java.util.*;
class ExceptionStack {
public static void someOtherMethod(String s) {
s = s.toUpperCase(); // Note "s" is null, so BANG NullPointerException
System.out.println (s);
}
public static void main (String[] args) {
String s = null;
someOtherMethod (s);
}
}
Below is the output generated as this program dies. Notice that is shows
the path from main into someOtherMethod(). This is invaluable debugging
information.
% java ExceptionStack
Exception in thread "main" java.lang.NullPointerException
at ExceptionStack.someOtherMethod(ExceptionStack.java:8)
at ExceptionStack.main(ExceptionStack.java:15)
Exceptions As Inner Classes
Today, we created the OutOfRangeException as an independent class, in
its own file. We could also have nested this exception class within the
ExceptionExample class. If the exception were qualified as "private",
then it would only be useful within the class -- meaning that none of the
public methods could throw the exception. But, if it were declared as
"public", it could be thrown. Within the class, it would be known as
OutOfRangeException. But, outside of the class, it would be known
as ExceptionExample.OutOfRangeException.
Notice how, in this case, the .-scope operator identifies the exception as
being nested. This, among other things, prevents a name-space conflict if
more than one class happens to define an exception with the same name.
Similarly, by nesting an exception and making it private, we can hide it
completely. It doesn't pollute the name space outside of the class.
It can't be used outside of the class. It is basicalyl invisible --
except that it can be used internally.