Carnegie Mellon University, Pittsburgh, PA
The goal of the work presented below is to model individual differences in working memory (WM) at a detailed level and subject by subject.
The organization of this page is as follows:
* Describe a task and experiment designed to exercise WM
* Develop an ACT-R model of that task
* Show that the model captures aggregate performance
* Use a single model parameter to capture the observed variability across subjects
* Fit the model to individual subject data
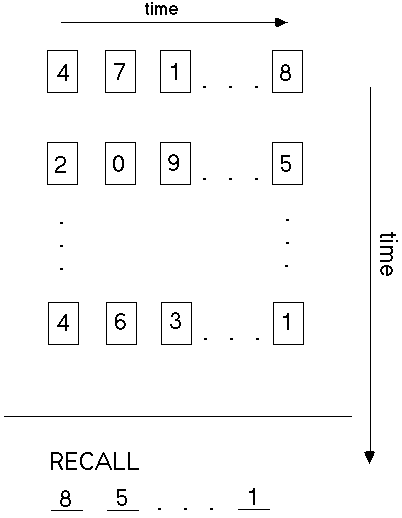
The task below is a digit working memory task. Digits appear on the screen one at a time, and participants must read them aloud. The final (rightmost) digit in each string (row) must be stored for later recall. At the "RECALL" prompt, the participant must say the string-final digits in order. (Skipping a recall position is allowed.)
In this experiment, we varied the factors:
* Digits per string (4 or 6)
* Number of strings AKA total number of recall digits (3, 4, 5, or 6)
* Rate of presentation per digit (0.5 s or 0.7 s)
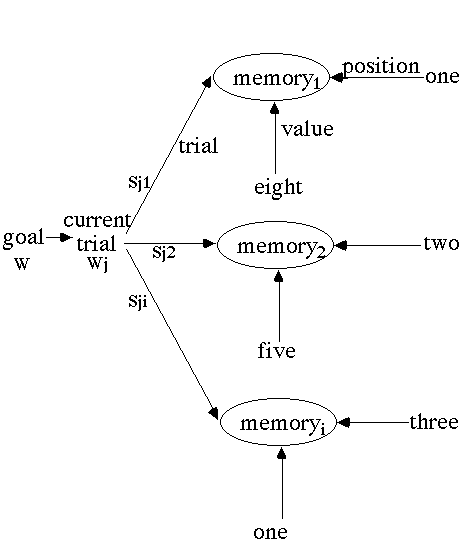
There were two goals in our model of the task: a read-digits goal and a recall-digits goal. The picture below is the model's representation of a recall-digits goal; it has slots for the trial and position currently being recalled.
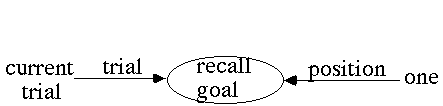
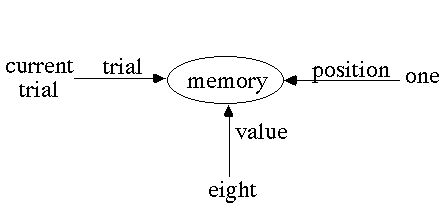
Also important is the model's representation of the memory digits. An example is shown below with slots for trial, position, and value.
Below are English versions of the production rules in the model. They specify the sequence of processing.
Read:
IF goal is to read a digit & digit is on screen
THEN say that digit
Store:
IF goal is to read a digit & digit d is on screen, is in last column, & has been read
THEN store d in memory & prepare to rehearse
Rehearse:
IF goal is to read a digit &
digit is in the position to be rehearsed
THEN rehearse that digit
Recall:
IF goal is to recall digit in position p of trial t &
digit d "matches" and has not been recalled
THEN say digit d
In addition, the model contains No-recall, Next-item, Say productions
The activation of a memory element i (Ai) determines its probability of recall and latency to be recalled:
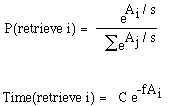
The activation of a memory element, in turn, depends on several factors: its history of use (see B below) and how much source activation it receives from the goal (this is a function of W, the total amount of source activation available for a given individual). The amount of source activation that reaches a memory element also depends on the strength of its links (Sji, these are smaller the more links connected to a given node-- that is, activation will be smaller when there are more memory elements in the span). The picture and equations below summarize the role of W and digit span in activation. The key result is that performance measures (such as proportion recall and latency to recall) are non-linear functions of W and span size.
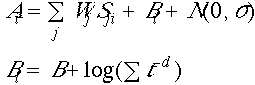
The dependent variable in all figures below is proportion of trials with perfect recall. Simulated data (i.e., predictions of the model) come from our computational model of working memory, with W (total amount of attentional capacity) as the model's individual difference variable.
The observed data reveal a large effect of number of strings on the proportion of trials recalled correctly. There is also a main effect of rate of presentation such that participants show better recall on slower trials than on faster trials. This may seem counter-intuitive because slower trials imply a longer delay to recalling the final digits. However, if participants rehearse the final digits at the end of each string (as our model does), the slower trials will allow more time for rehearsals. Finally, the number of digits per string did not have a large effect on recall performance.
Figure 1 shows the observed data (plotted by condition) as filled squares and the simulated data (also plotted by condition) as open squares. The simulated data were obtained by using the default parameters prescribed by the ACT-R theory. [That is, we are not presenting the model's best fit.] To produce the simulated data, we ran the model once for each subject (N=26) and plotted the average performance of the simulations, by condition.
Figure 1. Model's fit WITHOUT individual differences
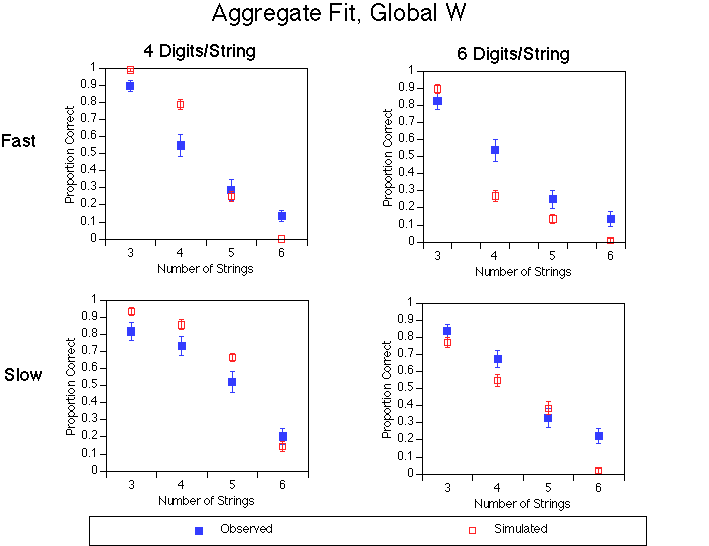
Note that this simulation does not take into account individual differences. All of the simulation runs used the same fixed value of W (=1). Nevertheless, the model provides an adequate fit to the data: It shows an effect of the various factors of our experiment with R^2 = 0.88. There are some systematic deviations, however, including the fact that the simulated data have much smaller standard error bars than the observed data. (The best-fitting line is Observed = 0.71 * Predicted + 0.16.) This suggests individual differences may be important.
Incorporating individual differences into our model
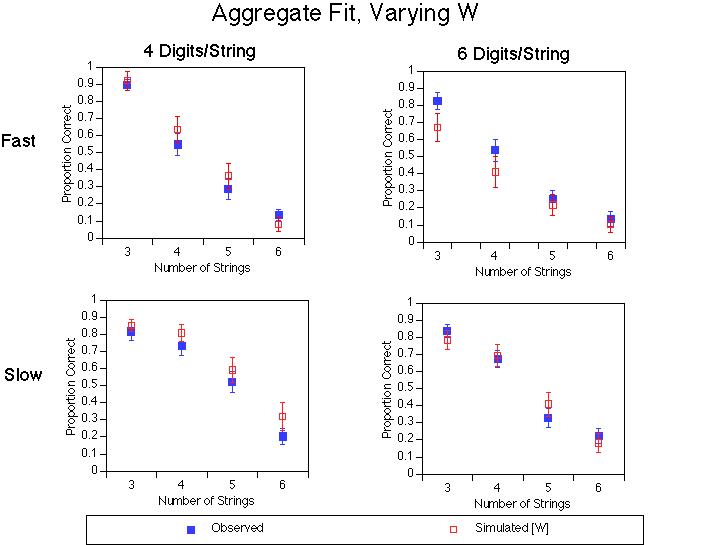
To incorporate individual differences into our model, we used two approaches. Our first approach involved running simulations of the model in which the W parameter was not fixed but rather varied from simulation run to simulation run. That is, we maintained the other parameters at their previous values but took W as drawn from a normal distribution centered at the default value. This provided more variability in our simulation results, and it also changed the mean level predictions of the model. Figure 2 shows the observed data as in Figure 1, but the model predictions are now taking into account individual differences. Note that the overall fit is much improved and the simulations' standard error bars are now comparable to the observed data. Here, R^2 = 0.92 and the best-fitting line is Observed = 0.95 * Predicted + 0.02. [Note: again, this is not even an optimal fit.] The difference in the simulation results between Figures 1 and 2 emphasizes the importance of incorporating variability in models of working memory: When there are non-linearities in a computational model, adding indiviudal differences not only increases the variability of the model's predictions but affects the mean level of its predictions as well.
Figure 2. Model's fit WITH individual differences included
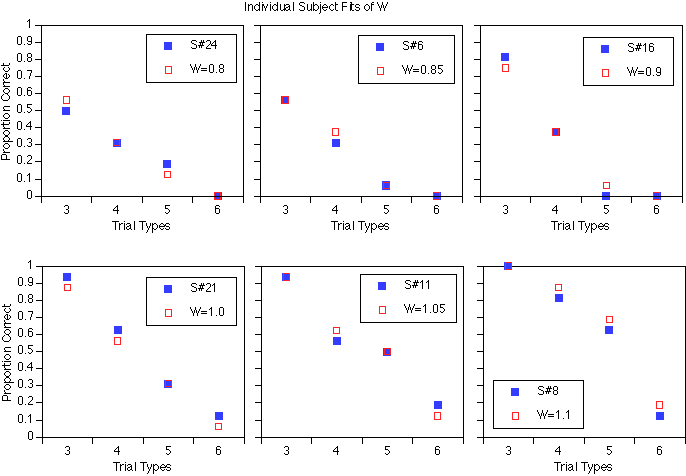
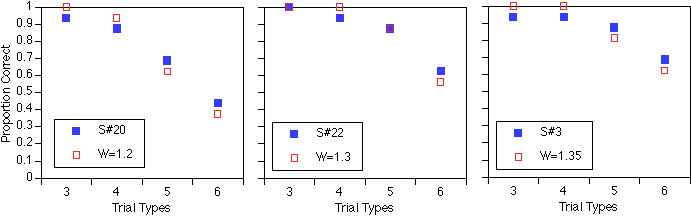
Our second approach to incorporating individual differences into our modeling efforts involved fitting the W parameter to individual subject's data. This approach is rarely taken but is necessary to ensure that one's theoretical or computational model can accurately capture the individual differences exhibited by particular subjects. Each panel in Figure 3 shows an individual subject's proportion of trials correct (for the four trial types specified by the "number of strings" factor). With each subject's observed data is a set of predictions from the model, for a corresponding value of the W parameter. Notice that even at the individual subject level, our model is capturing performance quite well. [caveat: the model predictions here are based on a small number of simulation runs so, just like the subject data, they are subject to some amount of noise. Also, keep in mind that these are not optimal fits but rather just a demonstration that the model's predictions under different values of W correspond to actual individual subject's profiles.]
Figure 3. Individual model fits to individual subject's data (varying only W)
Modeling a working memory task at this detailed and individual subject level can:
* improve our understanding of the impact of working memory
* provide rich set of constraints in modeling individual differences
* make parameter values more meaningful
* demonstrate the importance of variability
* enable within-subject, across-task fits
For more information, email Marsha Lovett at lovett+@cmu.edu