12.70 (a) To determine whether the rate of increase of mean salary with experience is different for males and females we test:
H0: b4 = b5 = 0
HA: At least one of the parameters b4 and b5 is not 0.
(b) To determine whether there are differences in mean salaries that are attributable to gender, we test we test:
H0: b3 = b4 = b5 = 0
HA: At least one of the parameters b3, b4 and b5 is not 0.
12.71 To determine if the mean salary of faculty members is dependent on gender, we test:
H0: b3=b4=b5=0
HA: At least one bi ¹ 0, i= 3, 4, 5
The test
statistic is ![]()
The rejection region corresponds to a=0.05 in the upper tail of the F-distribution with v1 = 3 and v2 = 194. From Minitab, F0.05 = 2.65, so the rejection region is F>2.65.
Since the observed value of the test statistic does not fall in the rejection region, H0 is not rejected. There is insufficient evidence to support the claim that the mean salary of faculty members is dependent on gender at a=0.05.
15.7 (a) This is an observational experiment. The economist has no control over the factor levels or unemployment rates.
(b) This is a designed experiment. The manager chooses only three different incentive programs to compare, and randomly assigns an incentive program to each of nine plants.
(c) This is an observational experiment. Even though the marketer chooses the publication, he has no control over who responds to the ads.
(d) This is an observational experiment. The load on the facility’s generators is only observed, not controlled.
(e) This is an observational experiment. One has no control over the distance of the haul, the goods hauled, or the price of diesel fuel.
Statistics in Action 14.1 The Consumer Price Index:
CPI-U and CPI-W
a. In each of the above three cases, explain why the index does not capture the noted effect.
(i)
The
index captures changes in good prices, but not changes in quantities
purchased. That is, since the index is
calculated based on the current price at the base year quantity, shifts in
consumer behavior from the purchase of one good to another will not be captured
unless and until the base year is changed.
(ii)
The
CPI is based on a typical “bundle” of goods and reflects quantities of those
goods purchased in the base year. The
sharp decrease in new product prices due to technological innovations clearly
reflects a “drop in price” that is valuable to consumers of such goods. However, since it takes time for the good to
be included in the bundle, that drop in price is not reflected by the CPI.
(iii)
The
index considers the price of commodities that are included in the composite
bundle of goods, but not the “value” received by consumers purchasing the
product (particularly when the index fails to reflect a dramatic change in the
quantity of the good purchased).
b. In each case, indicate whether the effect tends to cause the CPI to overstate or understate inflation. Justify your answers.
(i)
It
depends on the changes in the relative prices of the goods. If consumers are switching from a less
expensive to a more expensive good, the CPI will understate inflation. If they switch from a more expensive to less
expensive good, it will overstate inflation.
(ii) Overstate;
see above.
(iii) Overstate.
14.26 (a)
Data S&P
Length 68.0000
NMissing 0
Smoothing Constant
Alpha: 0.7
Accuracy Measures
MAPE: 6.140
MAD: 18.303
MSD: 614.069
Row Period Forecast
Lower Upper
1 65 598.780
557.880 639.681
2 66 598.780
557.880 639.681
3 67 598.780
557.880 639.681
4 68 598.780
557.880 639.681
(b)
Data S&P
Length 68.0000
NMissing 0
Smoothing Constant
Alpha: 0.3
Accuracy Measures
MAPE: 9.46
MAD: 30.29
MSD: 1612.08
Row Period Forecast
Lower Upper
1 65 545.570
481.653 609.487
2 66 545.570
481.653 609.487
3 67 545.570
481.653 609.487
4 68 545.570
481.653 609.487
14.34 (a) For
w = 0.7,
![]()
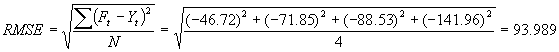
(b) For w = 0.3 (calculated analogously to above), MAD = 140.475
and RMSE = 144.748.
(c) Based on the MAD and RMSE values, the exponentially smoothed
forecasts using w = 0.7 are better than the forecasts using w = 0.3. Both the MAD and RMSE values for the
exponentially smoothed forecasts using w = 0.7 are less than the MAD and RMSE
values for the forecasts using w = 0.3.
Chattergee
Here is the SAS output
for the model
![]()
Model: MODEL1
Dependent Variable: LOG92
Analysis of Variance
Sum of Mean
Source DF Squares Square F
Value Prob>F
Model 1 56.29763 56.29763
156.837 0.0001
Error 35 12.56346 0.35896
C Total 36 68.86109
Root MSE 0.59913 R-square 0.8176
Dep Mean 4.13702 Adj R-sq 0.8123
C.V. 14.48215
Parameter Estimates
Parameter Standard T for H0:
Variable DF Estimate Error
Parameter=0 Prob > |T|
INTERCEP 1 0.769649 0.28635770
2.688 0.0109
LOG91 1 0.795988 0.06355975
12.523 0.0001
Here is a residual plot,
followed by the SAS program:
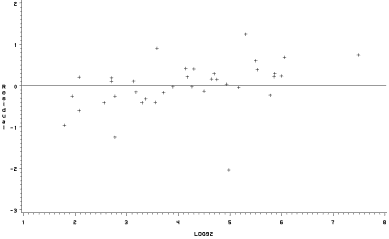
/*
90-786 Homework - December 2 */
libname
rdrive 'r:\academic\90786\SAS workshop';
data
adopt;
set rdrive.adopt;
proc
contents data=adopt;
/*
proc fsbrowse data=adopt; */
data
adopt2;
set adopt;
log91=log(adopt91);
log92=log(adopt92);
proc
contents data=adopt2;
proc
reg data=adopt2;
model log92=log91;
output out=stats residual=resid;
proc
contents data=stats;
proc
gplot data=stats;
plot resid*log92 / vref=0;
run;