Facial Expression Synthesis through AAE-CGAN¶
Goal¶
The purpose of this project is to recreate a facial expression of a person. The program is given a frontal facial image of an arbitrary identity, and it will output a facial image of a given expression in the following class (angry, disgust, fear, happy, sad, surprise, neutral). The expression is being generated without any extra information such as face landmark or same expression from a different face. The difficulty of this goal lies in two parts. First is to ensure photorealistic qualities of the output. Many generated outputs suffer from artifacts like wrong colored patch or distorted features of the face. Second is to preserve the identity of the face. It is important that after the generation important features of the face will be preserved.

Method¶
The method that I used is to combine two type of generative networks. The reason behind this design is to combine the benefits of both network and generate better face images.
Adversarial Autoencoder¶
The first type being Adversarial Autoencoder.
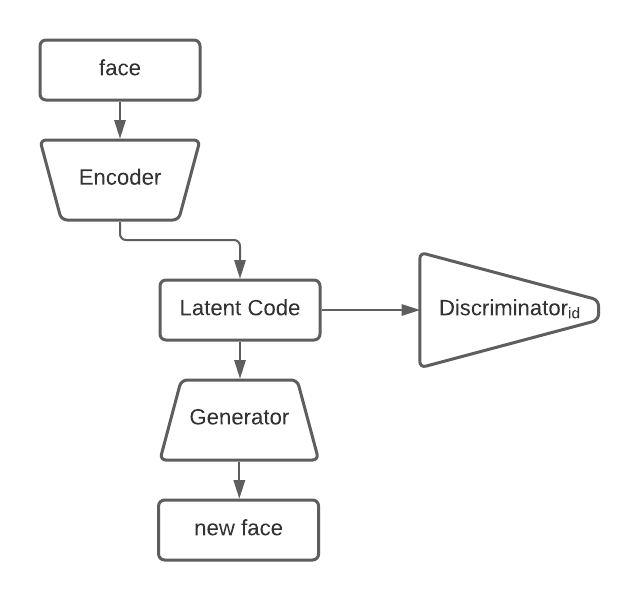
The purpose of the Adversarial Autoencoder is to encode the face features of the image and represent it in a latent code. The discriminator of AAE makes sure that the latent code is smooth and the identity of the face is preserved. The general drawback of this network is that it is rarely used for high quality photo generation. This is where the second part of the network comes in.
Conditional GAN¶
The second type of generative networks is the Conditional GAN.
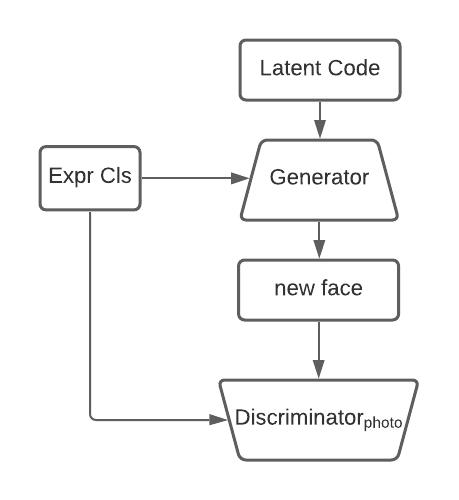
The purpose of the CGAN is to ensure the photorealistic qualities. By using conditional constraints in the network, the generator can generate faces based on a given class.
Our model¶
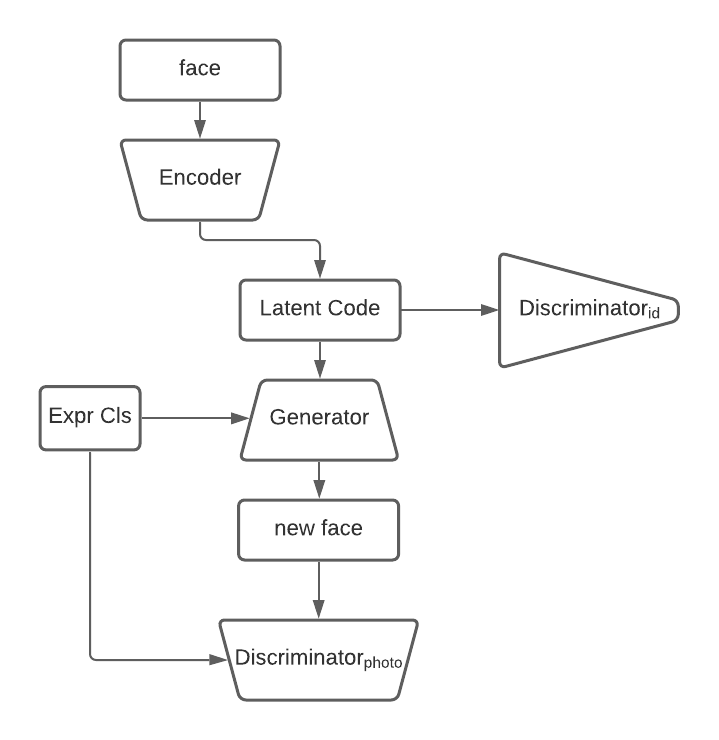
Above is the architecture of our network. It is a simple concatenation of two networks. It is worth noting that the training of this network will use the a weighted sum of two losses. One set of losses consists of encoder and discriminator of the AAE, and the other sets of losses consists of generators and discriminators of the CGAN.
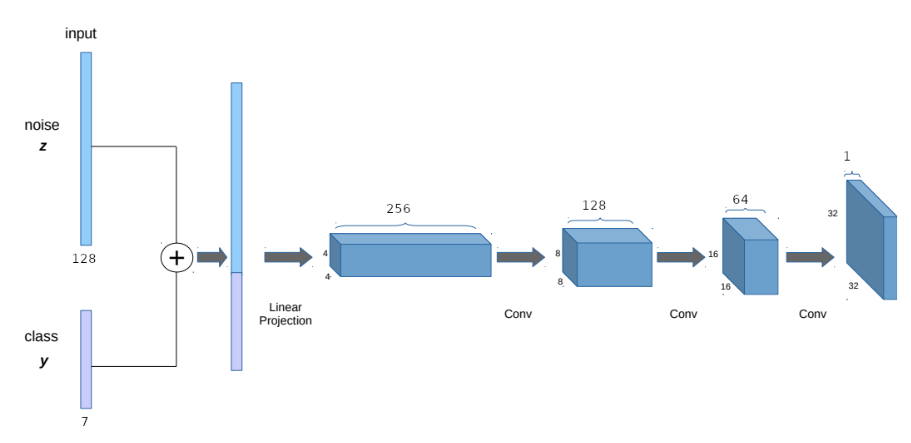
Above is the convolution structure of the generator. It follows the structure of a generator of Deep Convolutional GAN.
Also, in order to improve training stability and improve convergence rate, the training process uses Wasserstein GAN with gradient penalty. (Gulrajani, 2017)
Experiments¶
The experiments are conducted on two datasets: FER2013 and Toronto Face Dataset (TFD).


The FER2013 covers a larger variety of faces and is suitable for facial expression classification. However, many of the faces are not facing straight forward, and many faces have occusions that impede the training process of the network. The Toronto Face Dataset is more suitable for this task as the facial images are all frontal without occlusion and there are multiple expressions from the same face.
The hyperparameters used in the training are as follows. The network trains on a batch of size 32. The optimizer used is Adams. The experiments ran locally on a RTX 2080 GPU.
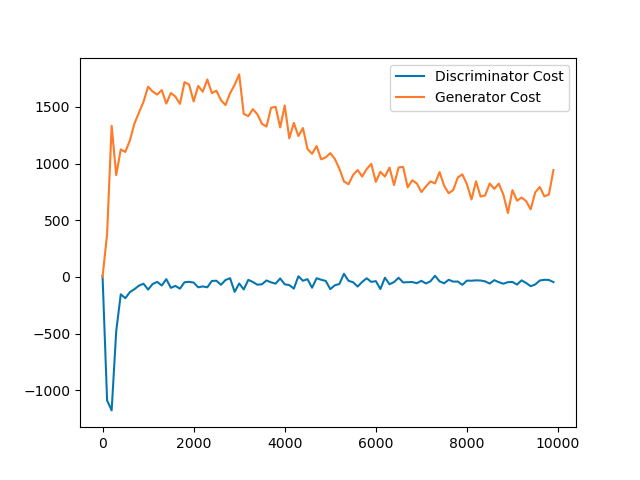
The training converges at around 10000 batches.
Results¶
Below are some of the results generated by this method.

The result to some extent generates different expressions of a given identity, and the outputs are consistent in its color and general features. However, the results are not entirely satisfactory as some expressions are unnatural and some expressions cannot be classified exactly as its intended calss. I suspect that there are a couple of reasons to this outcome. First, the combination of two networks results in a more complicated network and the training is harder to converge. Second, the total combined loss is a relatively naive weighted sum of two lossed and the training process might benefit from more thought out formulation of losses. Third, the training can be split in to two parts where each part of the network can be trained seperately to a good state, after which the weights can be loaded as pretrained weight and do a joint training in a second iteration.
Summary¶
In this project, I present a new method for facial expression synthesis by combining two generative network structures to generate better facial images. I have generated some initial promising results and there are room for improvements. I can continue to work on this project by designing more suitable loss functions, designing new joing training process and testing other datasets like CelebA on this method.