Creating implicit 3D representations from point clouds and/or RGB images
Divam Gupta (divamg)
Tarasha Khurana (tkhurana)
Harsh Sharma (hsharma2)
The aim of the project is to take a single RGB image, along with the point cloud and create a 3D model out. Rather than explicitly creating a mesh or a 3D model , we learn a neural representation. That learned representation can be used to render the learned model at different views. For that we use various models like NeRF and vanilla CNN based rendering.
We tackle the problem of densifying sparse modalities of either RGB image or pointclouds. We make the help of various models such neural radiance fields (NeRF) for representing the underlying radiance field of a scene. We show our approaches for superresolving and discuss the accompanying challenges to these methods.
Problem statement
Given an RGB image and a point cloud we aim to create a 3D representation. The RGB image can be used to create an RGB point cloud from the Lidar point cloud. We can either use the point clouds as voxels as an explicit input to the model, or we could generate multiple views from the RGB point cloud by projecting it along different camera views.
Overview of the models
- Sparse input NeRF model
- Context NeRF model
- Learng a latent representation vector and using a CNN to render that 3d representation.
- A GAN based model to learn and render the 3D representation.
Background: Neural Radiance Fields
We primarily try to use neural radiance fields or NeRF for representing the radiance field of a scene. These encode a scene as a continuous volumetric radiance field f of color and density. Specifically, for a 3D point and viewing direction unit vector , f returns a differential density and RGB color : . The volumetric radiance field can be rendered into a 2D image via first sampling 5D coordinates (location and viewing direction) along camera rays and feeding those locations into an MLP to produce a color and volume density. Given these sets of colors and densities, volume rendering techniques can be used to composite these values into an image.
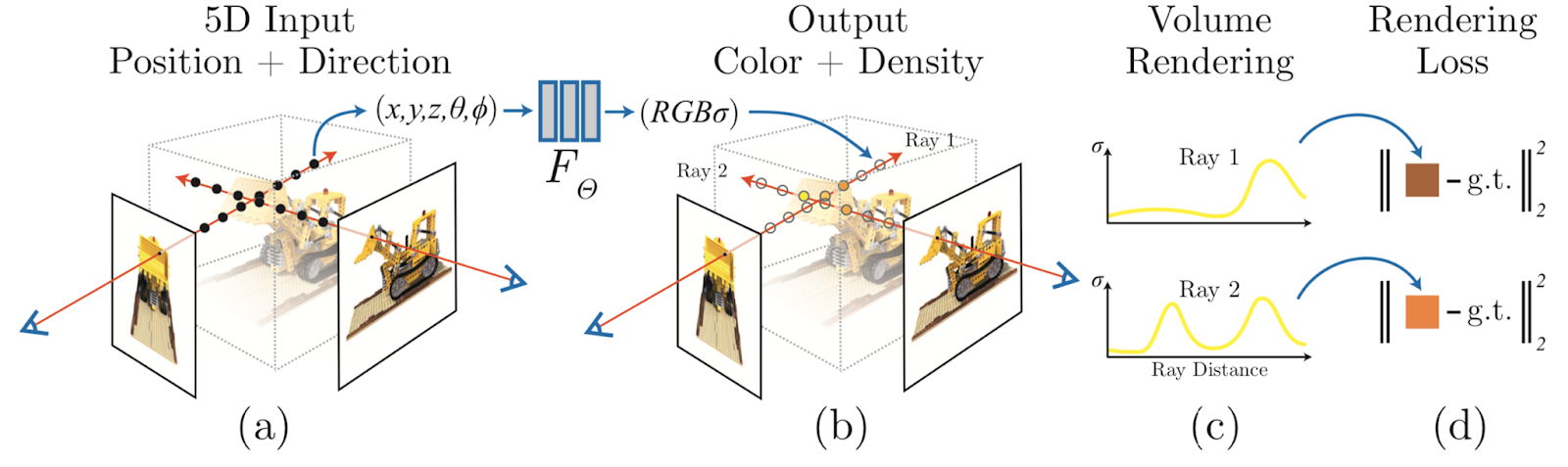
Intuitively an implicit radiance field function can help in tasks such as superresolution as parts of the image that may not be visible from one view could be from another. However, the results on trying to synthesize a higher resolution image directly using the learnt radiance field results in artifacts and we try to resolve these issues using coarse-to-fine registration and self attention mechanisms.
Super-resolving RGB Images
As our first experiment, we try a NeRF based model to learn from sparse input images of multiple views. This is coarsely equivalent to training on a spase projection images from an RGB point cloud.
Coarse-to-fine Registration
- Intuition: When filling missing pixels of an image, gather a global context by coarse registration and then reconstruct/synthesize finer details by fine registration.
- Disable higher frequencies in the positional encoding at the start of training
- Gradually introduce higher frequencies during training

Implementation:
Linearly increase the weight of the positional encoding from 0 to 1 from epoch 40 to epoch 80. The idea is that super-resolution can be thought of as hole-filling or filling in missing pixels. If an image is to be super-resolved by 2x, then this is the same as filling in every alternate row and column between the rows and columns of the given low-resolution image. We introduce missing pixels in the image in three ways:
- 'random': Randomly remove 50% of all the pixels in an image during training.
- 'patch': Consistently mask out the central 1/10th region of all the images.
- 'alternate': Mask out alternate rows and columns. This simulates super-resolution.
We first start by looking at the performance of NeRF when only a sparse input is given. This will be followed by our coarse-to-fine registration scheme which unfortunately does not work and hence, we are not able to appropriately superresolve images.
Behaviour of NeRF on Sparsifying RGB Input
| Property | w/o coarse-to-fine (PSNR, dB) |
|---|---|
| NeRF | 27.5 |
| NeRF (50% masked) | 26.9 |
| NeRF (masked patch) | 23.4 |
| NeRF-alternate (super-resolution) | 25.8 |


With Coarse-to-fine Registration
| Property | w/o coarse-to-fine (PSNR, dB) | w/ coarse-to-fine(PSNR, dB) |
|---|---|---|
| NeRF | 27.5 | 24.8 |
| NeRF (50% masked) | 26.9 | 23.1 |
| NeRF (masked patch) | 23.4 | 20.6 |
| NeRF-alternate (super-resolution) | 25.8 | 22.2 |

Going from Point Clouds to an implicit 3D representation
After running the experiment for training on sparse images where sparsity is artificially generated, we try experiments with real RGB point clouds.
We take a single RGB image from NYUv2 Depth dataset along with its corresponding RGB point cloud in camera coordinates. We generate images from new views using just this single RGB point cloud. These new views contain holes which we try to fill with the above model.
Implementation:
Random poses are generated with a 10 degree noise in rotation and 10cm noise in translation. We train the NeRF model with white background set to True, hence the outputs look different from the original image. The model is able to synthesize the scenes coarsely such that the artifacts from projecting into new view go away but the reconstruction is not fine enough.








Context NeRF
We experiment with a setting of a NeRF where we train across multiple images of different models rather than multiple views of the same model. This idea is similar to the pixelNeRF, and is supposed to make the network learn some priors from the dataset.
This didn't seem to capture the pointcloud and images' represenation well, and the resulting renderings are not at all meaningful. We use the ShapeNet dataset for this task.
The Point cloud is first mapped to a binary Voxel grid of size 32x32 and then passed to a 3D CNN to get the point cloud context vector. The input image is encoded to a context vector by passing to a 2D CNN.


Non-NeRF model
We also try using an encoder-decoder model which takes an input image and pose as input and outputs a new view. The model takes an image and point-cloud as input to generate a 3D representation vector. Similar to the above model, the Point cloud is first mapped to a binary Voxel grid of size 32x32 and then passed to a 3D CNN to get the point cloud representation vector. The input image is encoded to a representation vector by passing to a 2D CNN.
The concatenated output is passed to a Pose transformation MLP which learns to transform the 3D representation to the new given pose.
A rendering CNN which is a standard ConvNet with transposed convolutions is used to render the 3D input representation

We can see that the model is able to learn a decent 3d representation from a single input.
The first column is the input to the model, the 2nd column is the actual image of the new pose, the 3d column is the 3D render along the new pose.












Visualizing the learned 3D representation.
For visualizing the learned 3D we render the representation from multiple views
Here all the 3D views are generated from a single input image.









GAN Based Model
Now we also experiment with combining the above model with a GAN. Here we also add an adversarial loss along with a discriminator. The discriminator takes the generated image along the new pose and the input image to discriminate.





We tried several different hyper parameters but we observe that GAN is not significantly improving any results.
References
- Mildenhall, Ben, et al. "NeRF: Representing scenes as neural radiance fields for view synthesis." European Conference on Computer Vision. Springer, Cham, 2020.
- Yu, Alex, et al. "pixelNeRF: Neural Radiance Fields from One or Few Images." arXiv preprint arXiv:2012.02190 (2020).
- Lin, Chen-Hsuan, et al. "BARF: Bundle-Adjusting Neural Radiance Fields." arXiv preprint arXiv:2104.06405 (2021).