Return to the lecture notes index
February 1, 2008 (Lecture 9)
Reading
- Coulouris, et al: 11.4
- Chow and Johnson: 4.1.5, 12.2.2
Multicast
A Multicast message is a one-to-many message. It is much like a
broadcast, but it directed to a much smaller collection of hosts.
These hosts may be on the same network, or they may be on different
networks.
Today we are going to discuss implementing multicast as an
application-level protocol above a reliabel unicast. Specifically,
we are going to ponder the order in which the messages arrive, and
how we can take control and ensure that the application receives
messages in the right order -- for various definitions of
"the right order."
If you take, or have taken, 15-441, you probably did or will discuss
the implementation of multicast. The difference is that
15-441 considers an efficient network-layer implementation using
router trees, whereas we are discussing an application-layer
implementation and are more concerned with ordering guarantees
than the duplication of messages.
Ordering Guarantees
When we are multicasting from one host to many hosts, the message may
arrive at each of the hosts at a different time. As a result, if a
single host dispatches several multicast messages, they may get
"crossed in the mail". The situation can become further tangled
if several hosts are multicasting. Do you remember our discussion
of causality -- as we used to say in CEDA debate, "cross-apply it here".
Depending on the nature of the interaction of the hosts of the
distributed system, we may or may not be concerned with the ordering
of the messages. For example, if we know that every message will be
completely independent of every other message, a simple reliable
multicast will do -- we don't need to do anything special to
ensure that the messages arrive in any particular order.
But what if our system isn't quite so relaxed. It may be the case that
each host expects its own messages to be received in the order in which
they were sent, but that it doesn't matter how they are interleaved with
messages from other hosts. This is known as FIFO ordering.
A stricter ordering requirment is to ensure that all causally related
messages, independent of the host, are received in the order in which
they were sent. Earlier we spoke about detecting causality violations.
Now we are discussing the prevention of these violations by enqueing
messages and delivering them to the application in the proper order.
The strictest ordering requirement is total ordering. Total
ordering requires that the messages be delivered in the same order
as if they would be if the communication was instantaneous. In other
words, the messages should be received in the same order they would be
if messages were received at exactly the same time that they were sent.
A reliable, total ordering multicast is known as an
atomic muticast. By assuming that the unicast is reliable, we
will be constructing an atomic multicast.
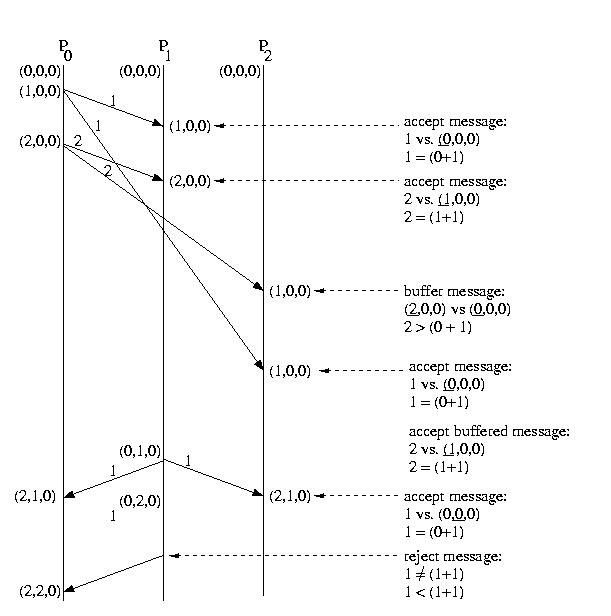
FIFO Multicast Protocol
We can ensure FIFO ordering in our mutlicast protocol by using
a per source sequence number. Each host maintains a counter and
of messages sent and sends this count, a sequence number, with each
multicast message.
Each potential receiver maintains a queue for each potential sender
(or at least the ability to create such a queue). Each potential
receiver also maintains the "expected sequence number" associated
with each possible sender. Since the host should receive all mutlticasts,
this number should be incremented by exactly one with each multicast
message from a particular host.
When a multicast message is received, the sequence number is compared to
the expected sequence number. If the sequence number is as expected, the
message is passed up to the application and the "expected sequence number"
associated with the sender on the receiver is incremented.
If the sequence number of the message is lower than the expected sequence
number, the message is thrown away -- it is a duplicate of a message that
has already been received.
If the sequence number of the message is higher than the expected
sequence number, the message is queued -- it is not yet passed
up to the application. The reason is that one or more earlier messages
from the same sender have yet to arrive.
Once the expected message has arrived, the queue is check. This queue
is probably maintained as a priority queue sorted by sequence number.
Messages are dequeued and passed up to the application until the queue
is empty, or the next message in the queue is not the "expected message".
Below is an example of this protocol at work:
Casual Ordering Multicast Protocol
We ensure that messages are delivered without causality violations
as we did before -- by buffering messages that arrive too early.
We determine if a message has arrived too early using a vector timestamp
similiar to the one we used to detect causality violations.
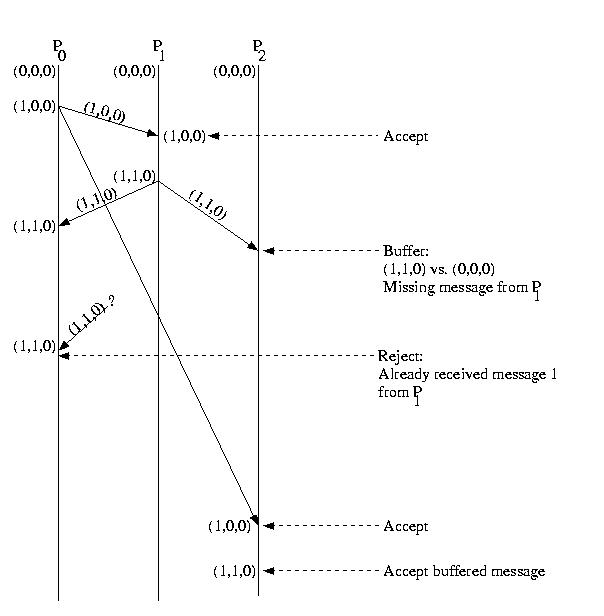
The key observation is that with a multicast protocol, all hosts within
the group should (eventually) see the same messages. As a consequence,
each host should see the same number of messages from each other host.
So, our vector contains one entry for each host. This entry counts
the total number of messages received from the corresponding host.
The entry for a host that corresponds to itself is used to count the
messages it has sent.
Each host sends a copy of its vector with each message and compare the
sender's vector with its own on receive:
- If any entry in the sender's vector, that was sent as a "timestamp"
with the multicast message is greater than the corresponding
entry in the receiver's local copy fo the vector, the receiver
buffers the message. This is because the sender has received
a message, whcih is potentially causally related to the
message it subsequently sent, that the reciever has not yet
received. If the incoming message were passed up to the application,
a causality violation might result.
- If the sender's entry in the message's timestamp is more than
one greater than the sender's entry in the local time vector,
the message is also buffered. This ensures that the protocol
ensures FIFO ordering.
- If the sender's entry in the messages timestamp is less than the
sender's entry in the local timestamp, the message is rejected --
it is a duplicate.
- If none of the above are true, the message is accepted. Accepting
a message offers the opportunity to dequeue previously enqueued
messages, if they can now be accepted.
Below is an example of the causal ordered mutlicast protocol:
Total Order Multicast
Total ordering requires that all messages are seen by all hosts in the same
order. This could be easily achieved if we had a global clock or counter
that could place serial numbers on messages. Then multicasts would just
be accepted in order of serial number, and buffering could be used to
handle missing messages. Some sytems emulate this approach using a
central sequence number server.
For now, we'll consider a distributed approach that can function in
light of differing local times (serial numbers), called the
two-phase multicast. In this approach, local times are used.
The local time is incremented any time an operation is
performed. Any time a system discovers that another system has a greater
time, it resets its own time to the greater time.
Here's how it works:
- The local time is incremented. The message is sent containing the
local time.
- The receiver buffers the message. It then sets its local time to
the time of the sender, if the sender's time is higher. increments its
local time, and sends an ACK that contains the local time.
- The receiver waits until it has received all of the replies. It then
determines the highest local time among the ACKS, and resets its
clock, if necessary. It increments its clock and sends a message
to all of the original recipients containing the "commit time."
This is the time at which the recipient considers the message to
have been received.
- Applications on the recipient host can see the message only after all
messages received between the "acknowledgement" and "committment"
of the message have been committed. This ensures that they won't
receive earlier committment times.