Return to the lecture notes index
January 18, 2008 (Lecture 3)
Reading
- Coulouris, et al: Section 5.1-5.3
- Chow and Johnson: Section 4.1-4.2
Message Passing
Early and rudimentary distributed systems communicated via message
passing. This form of communication is very simple. One side packages
some data, known as a message and sends it to the other side where it
is decoded and further action may be taken. The format of the message and the
way in which it will be processed by the receiver are application dependent.
In some applications the receiver may respond by sending a reply message. In
other cases, this might not happen.
It is important to realize that the messages carry only data and are
typically represented in a way that is known only by the sender and receiver
-- there is nothing standard about it. Unless mitigating action is taken by
the designer of the message format or the implementer of the application,
the communication might not be interoperable across platforms, because
of representation differences (e.g. big-endian vs. little-endian).
This approach also makes it hard to reuse components of one distributed
system in other distributed systems, because there is really no concept of
a common library -- everything is "hand rolled".
Remote Procedure Calls (RPC)
Although message passing can be effective, it would be nice if there
were a more uniform, reusuable, and user-friendly way of doing things.
Remote Procedure Calls (RPCs) provide such an abstraction. Instead of
viewing the communication between two systems in terms of independent
exchanges of data, we back up a step and examine the overall behaviors
of the systems.
Often times the services of the system can often be decomposed into
procedures, much like those used in traditional programming. These
procedures accept certain types of information, perfomr some useful
operation, and then return a result. The RPC abstraction allows us to
extend this paradigm to distributed systems. One system can provide
remote procedure calls for use by other systems. From the applications
point of view, it can use these remote procedure calls much like local
procedure calls. Behind the scences, the RPC is actually connecting to
a remote host, sending it the parameters, performing an operation on that
remote host, and then returning the result.
This is very similar to a very specific use of message passing. In fact the
function invocation is a message from the client to the server. This message
names the function and also provides the parameters. After receiving this
message, the server performs the operation and sends a message back to the
client with a result. The client then treats this result as if it were the
return value from a local procedure call.
The important charachteristics of RPCs are these:
- They provide a very familiar interface for the application
developer
- They one way of implementing the commonplace request-reply primitive
- The format of the messages is standard, not application dependent
- They make it easier to reuse code, since the RPCs have a standard
interface and are separate from any one application-proper.
Limits of RPCs
From the perspective of the application programmer, RPCs operate much like
local procedure calls, but there are some important differences:
- A "call be address (reference)" is not possible, because the
two processes have different address spaces. Parameters that
otherwise might be passed by address are often passed by "in-out"
instead. In-out paramters are copied by value on procedure invocation,
and again upon return. The end result is that the calling procedure
has the new value of the data item. The difference in semantics
is that paramters passed by in-out retain their old value until
the function returns. Parameters that are passed by reference
can change value, even from the perspective of the calling function,
throughout.
- Addresses and other large objects are typically passed by address,
these need to be copied.
- Byte ordering issues (big-endian/little-endian) might need
correction
- Representation issues, sucha as ACII vs. EPCIDIC might
need mitigation.
- "Calls by (C++, et al) reference" require more work as does the
return of an object reference. This is because both sides don't
share either the same address space or the same mapping tables.
Marshalling and Stubs
The process of preparing and packaging the information for transmission
is known as marshalling (think of the marshal leading people at a
wedding). This often involves translating non-portable representations
into a portable or canonical form. In the case of Sun's implementation
of RPC, a set of conventions known as eXternal Data Representation (XDR)
is used.
In order to hide this process from both the application programmer and the
author of the RPC library, it is often implemented using automatically
generated stubs.
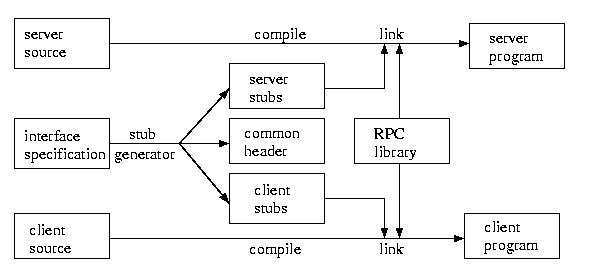
The process basically works like this. The programmer develops the
interface for the RPC. The stub generator takes this
interface definition and creates server stubs and client
stubs, as well as a common header file. The server stubs and
client stubs take care of the marshalling and unmarshalling of the
parameters, as well as the communication and procedure invocations.
This is possibly, because these actions are well defined given the
procedure's identity and parameterization. Once this is done, the
programmer can build the RPCs and the application. Each is linked
against the RPC library which provides the necessary code to
implement the RPC machinery.
This process is shown in the figure below:
RPC and Failure
The failure modes of RPCs are different than those experienced by
local function calls -- there are common failure modes! When was
the last time that you can remember a local function call failing?
I'm not asking when it was that you most recently observed a bug in
a function. I'm asking when it was that you most recently observed
the actual transfer of control fail. My point is that in conventional
systems this doesn't happen -- and if it should ever happen, it is
acceptable to do nothing, but roll over.
But this isn't the case in a distributed system. The communication to
the RPC server can fail. The reply from the RPC server can fail. The server
can crash. The client can crash. And worst of all, even if we know
that asomething bad happened, we may not know when. What to say?
Bad things happen -- but good software is prepared.
Please consider the situations shown below:
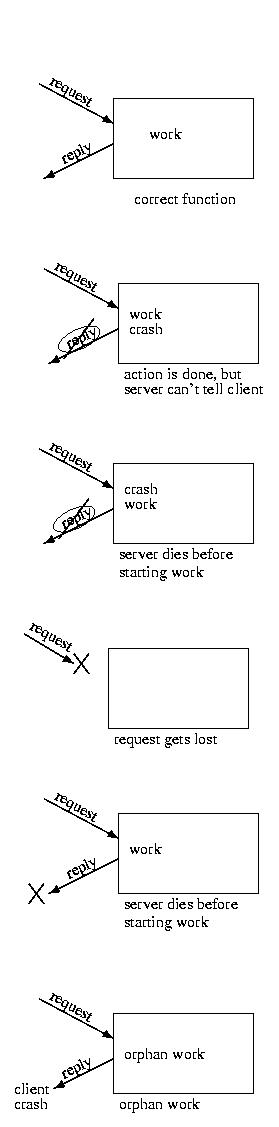
These failure modes lead to different semantics for RPCs in light of failure:
- exactly once -- the RPC will be executed exactly once -- never more,
never less. Althoguh this is most like local function calls, it is
very expensive to implement
- at most once -- if all goes well -- "Hurray! It worked!" Otherwise,
no big deal. The important thing is that the operation is never
repeated.
- at least once -- if all goes well -- "Hurray! It worked!" Otherwise,
keep repeating the operation -- even if there is a risk that
it might have happened already (e.g. lost ACK).
- idempotent -- The operation can be repeated without any change.
Often times at least once semeantics leads to the design of
idempotent operations.
Finding an RPC
RPCs live on a specific host, at a specific port. The port mapper
on the host maps from the RPC name to the port number. Typically when
a server is initialized, it registers its RPCs, and their
version numbers with the port mapper. A client will first connect to
the port mapper to get this handle to the RPC. The call to the
RPC can then be made by connecting to this port.
"Hello World!" RPC
Below are the source files for a simple "Hello World!" RPC program.
The server has a function which returns the string "Hello World!".
The client invokes this function remotely, and then prints out the
string that it received.
The helloworld.x file was fed to rpcgen, which in turn produced the
server and client stubs, helloworld_svc.c and helloworld_clnt.c, and
the common header file, helloworld.h.
Normally, the client code, the remote procredure's implementation,
and Makefile are created by the programmer from scratch. But, I actually
cheated here. "rpcgen -a" will create, in addition to the stubs,
skeletons for three more files: the Makefile, the client program, and
the remote procedure's implementation. I took the files it produced,
filled the remote procedure's implementation into the skeleton, and
slightly modified the client.
- helloworld.x:
The definition file fed to rpcgen
- Makefile:
The Makefile generated by "rpcgen -a"
- helloworld_client.c:
The client program's source, modified slightly from
the one generated by "rpcgen -a"
- helloworld_server.c:
The remote method's implementation, filled into the
skeleton provided by "rpcgen -a"
- helloworld.h:
The common header file generated by rpcgen
- helloworld_clnt.c:
The client stub produced by rpcgen from the helloworld.x file
- helloworld_svc.c:
The server stub produced by rpcgen from the helloworld.x file