Return to the lecture notes index
March 19, 2004 (Lecture 25)
Reading
- Chow and Johnson: N/A
- Coulouris, et al: N/A
Introduction To Process Migration: The Non-Distributed Case
Last class we discussed processor allocation, the selection of a processor
for a process. This class we are going to discuss process
migration, the movement of a process from one processor to another.
In many ways, process migration gives distributed systems the same freedom
that centralized systems enjoy to schedule processes efficiently.
For example, in a non-distributed multiprocessor system, the scheduler is
typically free to run any process on any processor. This enables it to
avoid the situation where some processors are idle and other processors
have long runnable queues. There is a cost associated with migrating
a process to a different processor. This cost is the loss of the
lines assocaited with the process in the processor's instruction a data
caches. The resulting cache misses amount to a migration penalty. But this
penalty is rather low, especially if one considers the penalty associated
with an unnecessarily idle processor. In many cases, non-distributed systems
simply neglect the cost associated with process migration.
The Costs of Process Migration in a Distributed Environment
Although the cost of process migration is so small that the topic is
often left out of introductory operating systems courses (as was the
case in 15-412), it is a compelling part of the discussion in
distributed systems.
So what are the costs associated with process migration in a distributed
system? Here are a few of the "biggies":
- Moving a process's virtual memory
- Forwarding a process's IPC (local and network) messages, and/or
informing the senders of the process's new contact information
- Moving information about a process's use of files. Even if we
assume some type of distributed file system, we still have
concerns: the open file table, the file descriptor table, the file
offset, dirty blocks in the buffer cache, &c
- Moving the process's user-level state: registers, stack, &c
- Moving the process's kernel-level state: pwd, pid, signal masks, &c.
These costs are not typically negligible. They are represent a sufficiently
high cost to make migration more work than it is worth -- the system is
more efficient without the dead-weight loss. In other cases, they make
the migration of the whole process too expensive. Although certain
aspects of a process might be migrated, other aspects of the process
remain on the original host. The remaining portions of the process
create residual dependencies -- the migrated process still relies
on the original host to provide the services that were not migrated.
Migration of Communication Channels
Let's assume that a migrating process is communicating with other processes
via some IPC mechanism. Since we're talking about a distributed system,
this communication may either occur between processes on the same host,
or those connected via a network. If a process migrates, this communication
must be able to continue.
There are two basic approaches to this problem -- they can certainly be
combined. The first approach is to inform "interested" processes of the
new location of a migrating process. What is an "interested" process?
An interested process is any process that is currently communicating
with the migrating process, or that already knows the location of the
migrating process and might potentially communicate with it in the future.
This approach is "clean" in the sense that it doesn't leave any residual
dependencies. But it can be a bit difficult. How might a server know
which clients know its location? It can also be expensive in the sense that
it might send many unnecessary message. Which of the other processes are
actually going to communicate with it in the future? Informing other
processes is likely a waste of time and bandwidth.
The other approach is to set up some type of link redirection or
forwarding at the original host of the migrating process. This
approach creates a residual dependency and can increase the latency
involved in sending messages to the migrated process, but makes the
process of migration itself cheaper.
A hybrid appraoch is certainly possible. For example, it might be possible
to set up link redirection, but also for the migrated process to inform
processes of its new location as part of replies to their redirected queries.
It might also be possible to set up link redirection, but also to
inform recent correspondents of the new address shortly before or after
migrating.
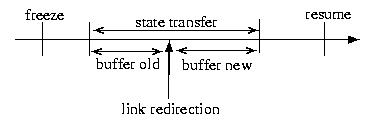
Any approach to migrating a process that can be involved in IPC will
involved buffering messages. Messages should be buffered at the
old location, until the new location is able to buffer them. The new
location should buffer them until the migration is complete, and the
migrated process can read them. This is depicted in the figure below:
It should also be noted that manipulating IPC for migrating processes
is more straightforward on those operating systems that use media
independent mechanisms for IPC than those that have different mechanism
for different types of links. For example, Mach ues the same IPC for
processes on the same host as for those connected via a network. By
contrast, most UNIX applications use a different interface for IPC than
for network communication -- of course it is certainyl possible to use
the socket API for both.
Migrating Processes with Open Files
At first it would seem like a fairly straightforward task to migrate
a process with oepn files -- and conceptually, it should be: show up
at the new host and re-open the files (assuming a DFS). But, in truth,
there is a great deal of state associated with an open file. Consider
the system-wide open file table, the cached inodes, dirty blocks that
may live only in the local buffer cache, &c.
If these sound like straightforward things to handle, consider migrating
either a parent or child process -- rememeber that fork()'d proceses
share the same file offset -- this would be a trick if they lived on
different hosts. Also consider a process that writes to a file. The dirty
blocks might live only in that host's block cache -- different DFSs
offer different consistency guarantees (more soon).
For this reason, it is often much easier to leave the process dependent
on the old host for file service. This isn't very clean -- it is again a
residual dependency. But it is much more straightforward than trying to
chase down all of the kernel state. And it makes some things (like proper)
fork() semantics doable at an affordable price.
Kernel State
The same logic as above applies to many of the services that a kernel
offers to processes. It is often easier to use leave a migrating process
dependent on a prior (or berhaps first) host for these services.
Some operating systems offer "checkpointing and recovery". This feature
allows all of a process's state to be saved to a file (much like a
persistent object) and then a new process to be created (restored) based
on this checkpoint file. This checkpoint file contains all of the "goods"
including the kernel material.
This feature can be used for migration: a process is checkpointed and then
killed. The checkpoint file is then shipped to a different host, where it
is "recovered".
Migration and Idle Workstations
One common application for migration is to make use of idle workstations.
In this case a process is migrated from the home host, where it
was "born" to an idle workstation. If the owner of the workstation should
return, the process is evicted back to the home machine. If the
home machine gets too busy, it might again migrate to an idle workstation.
The idea of a home machine makes soem things much easier -- for example
long link chains cannot occur, since processes must always pass through
the home machine to get to another host. Of course, it can also add a step
to the migration process, if the home machine is too busy to run an evicted
process.
To Migrate? Or Not To Migrate?
Migrating a process requires a substantial investment. Will it pay off?
Well, this depends. There are several things to consider:
- If the home host suffers from a bursty load, it may not make sense
to migrate a process -- the home host will be free again, soon.
- Processes with significant virtual memory or IPC usage are poor
choices for migration. The same is true for processes with many
open files.
- Since the recent past is the best indicator of the near future,
long running processes are better andidates than recent arrivals
-- long running processes are likely to continue to run for a
long time. Short lived processes are likely to complete shortly
after migration, offering little opportunity to amortize the
cost of migration over useful work.