If you examine the implementation of wait below, you will find that the wait function atomically releases the mutex and puts the thread to sleep. After the thread is signalled and wakes up, it reacquires the resource. This is to prevent a lost wake-up. This situation is discussed in the section describing the implementation of condition variables.
spin_lock s;
GetLock (condition cv, mutex mx)
{
mutex_acquire (mx);
while (LOCKED)
wait (c, mx);
lock=LOCKED;
mutex_release (mx);
}
ReleaseLock (condition cv, mutex mx)
{
mutex_acquire (mx);
lock = UNLOCKED;
signal (cv);
mutex_release (mx);
}
Condition Variables - Implementation
This is just one implementation of condition variables, others are possible.Data Structure
The condition variable data structure contains a double-linked list to use as a queue. It also contains a semaphore to protect operations on this queue. This semaphore should be a spin-lock since it will only be held for very short periods of time.
struct condition { proc next; /* doubly linked list implementation of */ proc prev; /* queue for blocked threads */ mutex mx; /*protects queue */ };wait()
The wait() operation adds a thread to the list and then puts it to sleep. The mutex that protects the critical section in the calling function is passed as a parameter to wait(). This allows wait to atomically release the mutex and put the process to sleep.If this operation is not atomic and a context switch occurs after the release_mutex (mx) and before the thread goes to sleep, it is possible that a process will signal before the process goes to sleep. When the waiting() process is restored to execution, it will enter the sleep queue, but the message to wake it up will be forever gone.
void wait (condition *cv, mutex *mx) { mutex_acquire(&c->listLock); /* protect the queue */ enqueue (&c->next, &c->prev, thr_self()); /* enqueue */ mutex_release (&c->listLock); /* we're done with the list */ /* The suspend and release_mutex() operation should be atomic */ release_mutex (mx)); thr_suspend (self); /* Sleep 'til someone wakes us */ mutex_acquire (mx); /* Woke up -- our turn, get resource lock */ return; }signal()
The signal() operation gets the next thread from the queue and wakes it up. If the queue is empty, it does nothing.
void signal (condition *c) { thread_id tid; mutex_acquire (c->listlock); /* protect the queue */ tid = dequeue(&c->next, &c->prev); mutex_release (listLock); if (tid>0) thr_continue (tid); return; }broadcast()
The broadcast operation wakes up every thread waiting for a particular resource. This generally makes sense only with sharable resources. Perhaps a writer just completed so all of the readers can be awakened.
void broadcast (condition *c) { thread_id tid; mutex_acquire (c->listLock); /* protect the queue */ while (&c->next) /* queue is not empty */ { tid = dequeue(&c->next, &c->prev); /* wake one */ thr_continue (tid); /* Make it runnable */ } mutex_release (c->listLock); /* done with the queue */ }
Monitors
A monitor is a synchronization tool designed to make a programmer's life simple. A monitor can be thought of as a conceptual box. A programmer can put functions/procedures/methods into this box and the monitor makes him a very simple guarantee: only one function within the monitor will execute at a time -- mutual exclusion will be guaranteed.Furthermore, the monitor can protect shared data. Data items declared within the monitor can only be accessed by functions/procedures/methods within the monitor. Therefore mutual exclusion is guaranteed for these data items. Functions/procedures/methods outside of the monitor can not corrupt them.
If nothing is executing within the monitor, a thread can execute one of its procedures/methods/functions. Otherwise, the thread is put into the entry queue and put to sleep. As soon as a thread exits the monitor, it wakes up the next process in the entry queue.
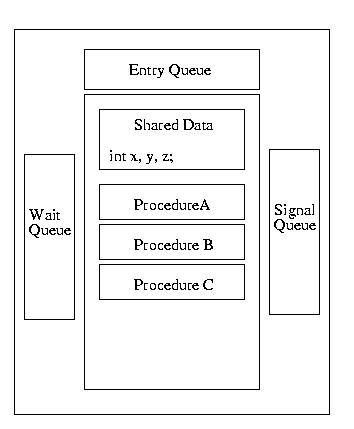
The picture gets a bit messier when we consider that threads executing within the monitor may require an unavailable resource. When this happens, the thread waits for this resource, using the wait operation of a condition variable. At this point, another thread is free to enter the monitor.
Now let me suggest that while a second thread is running in the monitor, it frees a resource required by the first. It signals that the resource that the first thread is waiting for becomes available. What should happen? Should the first thread be immediately awakened or should the second thread finish first? This situation gives rise to different versions of monitor sematics.
Monitors In Java
The Java programming language provides support for monitors via synchronized methods within a class. We are assured that at most one synchronized method within a particular class can be active at any particular time, even in multi-threaded applications. Java does not require that all methods within a class be synchronized, so every method of the class is not necessarily part of the monitor -- only synchronized methods of a class are protected from concurrent execution. This is obviously an opportunity for a programmer to damage an appendage with a massive and rapidly moving projectile.Java monitors are reasonably limited -- especially when contrasted with monitors using Hoare or Mesa semantics. In Java, there can only be one reason to wait (block) within the monitor, not multiple conditions. When a thread waits, it is made unrunnable. When it has been signaled to wake-up, it is made runnable -- it will next run whenever the scheduler happens to run it. Unlike BH monitors, a signal can occur anywhere in the code. Unlike Hoare semantics, the signaling thread doesn't immediately yield to the signaled thread. Unlike all three, there can only be one reason to wait/signal. In this way, they offer simplified Mesa sematics.
To wait for a condition, a Java thread invokes wait(). To signal a waiting thread to tell it that it can run (the condition upon which it is waiting is satisfied), a Java thread invokes notify(). Notify is actually a funny name -- normally this operation is called signal.
Monitor Examples in Java
In class we walked through these examples in Java from Concurrent Programming: The Java Language by Stephen Hartley and published by Oxford Univerity Press in 1998:The first example is a solution to the Bounded Buffer problem, also known as the Producer-Consumer Problem. This solution supports one producer thread and one consumer thread.
Please notice that the producer signals a waiting consumer if it fills the first slot in the buffer -- this is because the consumer might have blocked because there were no full buffers. The consumer follows a similar practice if it takes the last item in the buffer -- there could be a producer blocked waiting for an available slot in a buffer.
class BoundedBuffer { // designed for a single producer thread // and a single consumer thread private int numSlots = 0; private double[] buffer = null; private int putIn = 0, takeOut = 0; private int count = 0; public BoundedBuffer(int numSlots) { if (numSlots <= 0) throw new IllegalArgumentException("numSlots<=0"); this.numSlots = numSlots; buffer = new double[numSlots]; System.out.println("BoundedBuffer alive, numSlots=" + numSlots); } public synchronized void deposit(double value) { while (count == numSlots) try { wait(); } catch (InterruptedException e) { System.err.println("interrupted out of wait"); } buffer[putIn] = value; putIn = (putIn + 1) % numSlots; count++; // wake up the consumer if (count == 1) notify(); // since it might be waiting System.out.println(" after deposit, count=" + count + ", putIn=" + putIn); } public synchronized double fetch() { double value; while (count == 0) try { wait(); } catch (InterruptedException e) { System.err.println("interrupted out of wait"); } value = buffer[takeOut]; takeOut = (takeOut + 1) % numSlots; count--; // wake up the producer if (count == numSlots-1) notify(); // since it might be waiting System.out.println(" after fetch, count=" + count + ", takeOut=" + takeOut); return value; } }Fair Reader-Writer Solution
What follows is a fair solution to the reader-writer problem -- it allows the starvation of neither the producer, nor the consumer. The only tricky part of this code is realizing that starvation of writers by readers is avoided by yielding to earlier requests.
class Database extends MyObject { private int numReaders = 0; private int numWriters = 0; private int numWaitingReaders = 0; private int numWaitingWriters = 0; private boolean okToWrite = true; private long startWaitingReadersTime = 0; public Database() { super("rwDB"); } public synchronized void startRead(int i) { long readerArrivalTime = 0; if (numWaitingWriters > 0 || numWriters > 0) { numWaitingReaders++; readerArrivalTime = age(); while (readerArrivalTime >= startWaitingReadersTime) try {wait();} catch (InterruptedException e) {} numWaitingReaders--; } numReaders++; } public synchronized void endRead(int i) { numReaders--; okToWrite = numReaders == 0; if (okToWrite) notifyAll(); } public synchronized void startWrite(int i) { if (numReaders > 0 || numWriters > 0) { numWaitingWriters++; okToWrite = false; while (!okToWrite) try {wait();} catch (InterruptedException e) {} numWaitingWriters--; } okToWrite = false; numWriters++; } public synchronized void endWrite(int i) { numWriters--; // ASSERT(numWriters==0) okToWrite = numWaitingReaders == 0; startWaitingReadersTime = age(); notifyAll(); } }Counting Semaphores
Condition variables are great for modelling events or notificantions. But, what they don't do is allow us to keep track of available resources, waiting if there aren't enough. The sempahore is synchronization primative that is commonly used for this purpose. An instance of a sempahore is initially set to an integer value. After initialization, its value can only be affected by two operations:
- P(x)
- V(x)
P(x) was named from the Dutch word proberen, which means to test.
V(x) was named from the Dutch word verhogen, which means to increment.
The pseudo-code below illustrates the semantics of the two semaphore operations. This time the operations are made to be atomic outside of hardware using the hardware support that we discussed earlier -- but more on that soon.
/* proberen - test *. P(sem) { while (sem <= 0) ; sem = sem - 1; } /* verhogen - to increment */ V(sem) { sem = sem + 1; }In order to ensure that the critical sections within the semaphores themselves remain protected, we make use of spin-lock mutexes. In this way we again grow a smaller guarantee into a larger one:
P (csem) { while (1) { Acquire_mutex (csem.mutex); if (csem.value <= 0) { Release_mutex (csem.mutex); continue; } else { csem.value = csem.value 1; Release_mutex (csem.mutex); break; } } } V (csem) { Acquire_mutex (csem.mutex); csem.value = csem.value + 1; Release_mutex (csem.mutex); }But let's carefully consider our implementation of P(csem). If contention is high and/or the critical section is large, we could spend a great deal of time spinning. Many processes could occupy the CPU and do nothing -- other than waste cycles waiting for a process in the runnable queue to run and release the critical section. This busy-waiting makes already high resource contention worse.
But all is not lost. With the help of the OS, we can implement semaphores so that the calling process will block instead of spin in the P() operation and wait for the V() operation to "wake it up" making it runnable again.
The pseudo-code below shows the implementation of such a semaphore, called a blocking semaphore:
P (csem) { while (1) { Acquire_mutex (csem.mutex); // NOTE: This logic should look a great case for a CV wait. if (csem.value <= 0) { insert_queue (getpid(), csem.queue); Release_mutex_and_block (csem.mutex); /* atomic: lost wake-up */ } else { csem.value = csem.value 1; Release_mutex (csem.mutex); break; } } } V (csem) { // NOTE: This logic should look a great case for a CV signal. Acquire_mutex (csem.mutex); csem.value = csem.value + 1; dequeue_and_wakeup (csem.queue) Release_mutex (csem.mutex); }Please notice that the P()ing process must atomically become unrunnable and release the mutex. This is becuase of the risk of a lost wakeup. Imagine the case where these were two different operations: release_mutex(xsem.mutex) and sleep(). If a context-switch would occur in between the release_mutex() and the sleep(), it would be possible for another process to perform a V() operation and attempt to dequeue_and_wakeup() the first process. Unfortunately, the first process isn't yet asleep, so it missed the wake-up -- instead, when it again runs, it immediately goes to sleep with no one left to wake it up.
Take a look back at the implementation of the sepahore. Notice the use of a mutex to protect the atomicity of the evaluation of the predicate and queuing. Have you seen that before. Actually, step back even farther. Have you seen that logic before?
Yep. You've got it. It is really natural to implement semaphores using condition variables. Give it a try.
Boolean Semaphores
In many cases, it isn't necessary to count resources -- there is only one. A special type of semaphore, called a boolean semaphore may be used for this purpose. Boolean semaphores may only have a value of 0 or 1. In most systems, boolean semaphores are just a special case of counting semaphores, also known as general semaphores.The Producer-Consumer Problem
One classic concurrency control problem that is readly managued using semaphores is the producer-consumer problem, also known as the bounded buffer problem. In this case we have a producer and a consumer that are cooperating through a shared buffer. The buffer temporarily stores the output of the producer until removed by the consumer. In the event that the buffer is empty, the consumer must pause. In the event that the buffer is full, the producer must pause. Both must cooperating in accessing the shared resource to ensure that it remains consistent.The example below shows a general solution to the bounded buffer problem using semaphores. Notice the use of counting semaphores to keep track of the state of the buffer. Two semaphores are used -- one to count the available buckets and another to count the full buckets. The producer uses empty buckets (decreasing semaphore value with P()) and increases the number of full buckets (increasing the semaphore value with V()). It blocks on the P() operation if not buckets are available in the buffer. The consumer works in a symmetric fashion.
Binary semaphores are used to protect the critical sections within the code -- those sections where both the producer and the consumer manipulate the same data structure. This is necessary, becuase it is possible for the producer and consumer to operate concurrently, if there are both empty and full buckets within the buffer.
Producer() { while (1) { <<< produce item >>> P(empty); /* Get an empty buffer (decrease count) , block if unavail */ P(mutex); /* acquire critical section: shared buffer */ <<< critical section: Put item into shared buffer >>> V(mutex); /* release critical section */ V(full); /* increase number of full buffers */ } } Consumer() { while (1) { P(full); P(mutex); <<< critical section: Remove item from shared buffer */ V(mutex); V(empty); }Reader-Writer Problem
The Readers and Writers problem, another classic problem for the demonstration of semaphores, is much like a version of the producer-consumer problem -- with some more restrictions. We now assume two kinds of threads, readers and writers. Readers can inspect items in the buffer, but cannot change their value. Writers can both read the values and change them. The problem allows any number of concurrent reader threads, but the writer thread must have exclusiver access to the buffer.One note is that we should always be careful to initialize semaphores. Unitialized semaphores cause programs to react unpredictibly in much the same way as uninitalized variables -- execept perhaps even more unpredictably.
In this case, we will use binary semaphores like a mutex. Notice that one is acquired and released inside of the writer to ensure that only one writer thread can be active at the same time. Notice also that another binary mutex is used within the reader to prvent multiple readers from changing the rd_count variable at the same time.
A counting semaphore is used to keep track of the number of readers. Only when the number of readers is available can any writers occur -- otherwise there is an outstanding P() on the writing semaphore. This outstanding P() is matched with a V() operation when the reader thread count is reduced to 0.
It is important to note that the solution we provide below favors readers over writers. If processes are constantly reading, the writer(s) can starve indefinetely. It would certainly be possible to implement a similar solution that would favor writers at the expense of readers.
Writer() { while (1) { P(writing); <<< perform write >>> V (writing); } } Reader() { while (1) { P(mutex); rd_count++; if (1 == rd_count) /* If we are the first reader -- get write lock */ P(writing); /* Once we have it, it keeps writers at bay */ V(mutex); /* <<< perform read >>> P(mutex) rd_count--; if ( 0 == rd_count) /* If we are the last reader to leave -- */ V(writing); /* Allow writers */ V(mutex); } }