Return to the lecture notes index
February 28 (Lecture 14)
Credit
Much of today's discussion follows chapter 13 of the Chow and Johnson
textbook. Additionally, the figures used in class today were based on those
in this book. The bibliographic information is as follows:
Chow, R. and Johnson, T., Distributed Operating Systems & Algorithms,
corrected 1st edition, AWL, 1998, ISBN: 0-201-49838-3.
Recovery from Failure
As you know, distributed systems are very likely to suffer from failure.
This is a characteristic of their scale. Sometimes we have sufficient
redundancy to keep failures transparent. On other occasions, we need to
repair or replace failed processors and pick up where we left off before the
failure. This process is known as recovery.
Needless to say, recovery is a very important component of many real-world
systems. Recovery usually involves checkpointing and/or
logging. Checkpointing involves periodically saving the state of
the process. Logging involves recording the operations that produced the
current state, so that they can be repeated, if necessary.
Let's assume that one system fails and is restored to a previous state
(this is called a rollback). From this point, it will charge
forward and repeat those things that it had done between this previous
state and the time of the failure. This includes messages that it may
have sent to other systems. These repeated messages are known as
duplicate messages. It is also the case that after a rollback
other systems may have received messages that the revovering system
doesn't "remember" sending. These messages are known as orphan
messages.
The other systems must be able to tolerate the duplicate messages, such
as might be the case for idempotent operations, or detect them
and discard them. If they are unable to do this, the other systems
must also rollback to a prior state. The rollback of more systems
might compound the problem, since the rollback may orphan more messages
and the progress might cause more duplicates. When the rollback
of one system causes another system to rollback, this is known as
cascading rollbacks. Eventually the systems will reach a state where
they can move forward together. This state is known as a
recovery line. After a failure, cooperating systems must rollback
to a recovery line.
Another problem involves the interaction of the system with the real-world.
After a rollback, a system may duplicate output, or request the same
input again. This is called studdering.
Incarnation Numbers
One very, very common technique involves the use of incarnation
numbers. Each contiguous period of uptime on a particular system
is known as an incarnation of that system. Rebooting a system
or restarting a cooperating process results in a new incarnation.
These incarnations can be numbered. This number, the incarnation number,
can be used to eliminate duplicate messages. It must be kept in
stable storage, and incremented for each incarnation.
When a system is reincarnated, it sends a message to the cooperating
systems informing them of the new incarnation number. The incarnation
number is also sent out with all messages.
The receiver of a message can use the incarnation number as follows:
- If the incarnation number in the message is less than the
expected incarnation number, the message is a duplicate,
so it should be discarded.
- If the incarnation number in the message is greater than the
expected incarnation number, the sender is recovering, so
block accepting messages, until it informs us about its new
incarnation number.
- If the incarnation number is the same as the expected incarnation
number, accept the message.
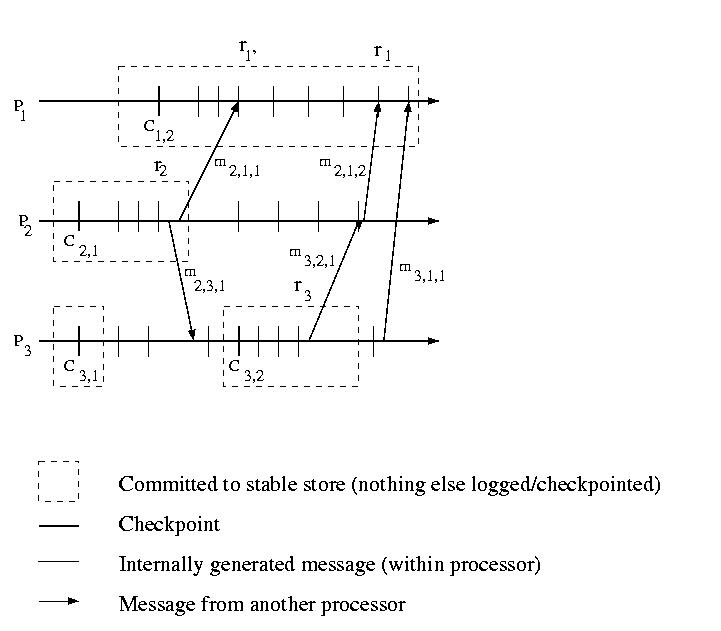
Uncoordinated Checkpointing
One approach to checkpointing is to have each system periodically
record its state. Even if all processors make checkpoints at the
same frequency, there is no guarantee that the most recent checkpoints
across all systems will be consistent. Among other things, clock
drift implies that the checkpoints won't necessarily be made at
exactly the same time. If checkpointing is a low-priority background
task, it might also be the case that the checkpoints across the systems
won't necessarily be consistent, because the systems may have cycles
to burn at different times or with a completely different frequency.
In the event of a failure, recovery requires finding the recovery lines
that restores the system as a whole to the most recent state. This is
known as the maximum recovery line.
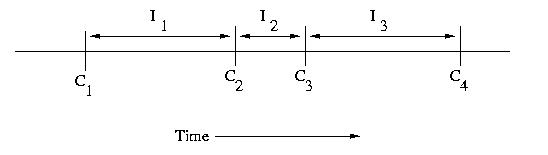
An interval is the period of time between checkpoints. If
we number checkpoints, C1, C2, C3,
C4, &c., the intervals following each of these checkpoints
can be labeled I1, I2, I3,
and I4, respectively. it is important to note
that the intervals need not be the same length.
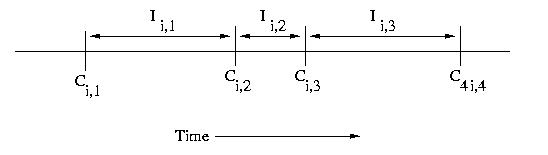
If we have multiple processors, we can use subscripts such
as Ci,c and Ii,c, where i is the processor number
and c is the checkpoint sequence number.
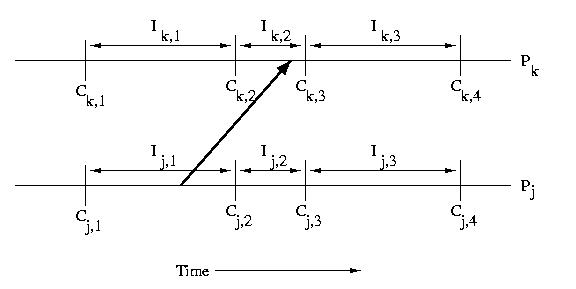
When a processor receives a message, that message usually causes it
to take some action. This implies that the processor that receives
a message is dependent on the processor that sent the message.
Specifically if a processor receives a message during an interval,
it is dependent on the interval on the sender's processor during
which the message was sent. This type of dependency can cause
cascading rollbacks.
In the example below, Ik,2 depends on Ij,1
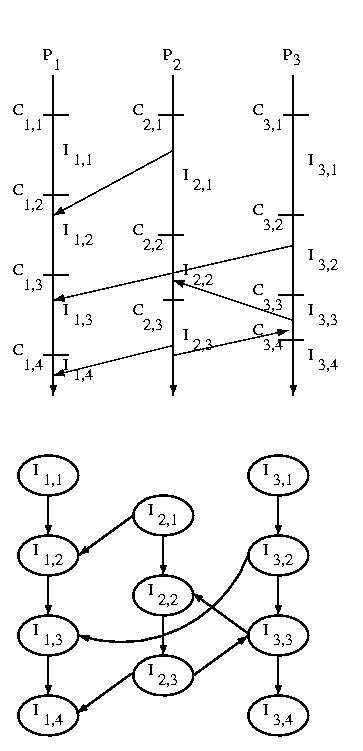
If we consider the messages sent among systems we can construct
an Interval Dependency Graph (IDG). If any intervals are
removed from the graph due to rollbacks or failures, we must
remove all intervals that they reference -- this is a transitive
operation.
The graph is constructed by creating a node for each interval,
and then connecting subsequent intervals on the same processor by
constructing an edge from a predecessor to its successor. Then
an edge is draw from each interval during which one or more messages
were received to the interval or intervals during which the message(s)
was or were sent.
The edge from one interval to its successor on the same processor
exists to ensure that we can't develop "holes" in our state
-- a hole would imply wasted checkpoints -- those before the
hole would be useless.
The edge from a receiver to the sender shows the dependency of
the sender on the receiver. Remember that the arrow goes the
opposite way in the IDG than it did when we showed the message
being sent earlier -- this is because the sender is dependent
on the receiver, not the other way around. If other actions
generate dependencies, they can be represented the same way.
Where is this graph stored? Each processor keeps the nodes and edges
that are associated with it.
How Do We Find The Recovery Line?
Very simply. Upon recovery, we tell other processors
what checkpoint we'll be installing. Then they rollback
to an interval independent of the lost intervals and
broadcast a similar message. This continues until
the recovery line is established.
Coordinated Checkpoints
We can decrease the number of rollbacks necessary to find a recovery
line by coordinating checkpoints. We'll discuss two methods for
doing this.
Recording Message Sequence Numbers
If messages contain sequence numbers, we can use them to keep
track of who has sent us messages since our last checkpoint.
Each time we make a checkpoint, we send a message to each
processor that has sent us messages since the last time we
checkpointed -- we depend on these processors.
When these processors receive our message, they check to see if
they have checkpointed since the last time they sent us a message.
If not, they create a checkpoint, to satisfy our dependency in the
event of a failure.
Synchronized Clocks
Another method for coordinating checkpoints is to take advantage
of synchronized clocks, if available. Each processor creates a
checkpoint every T units of time. Since even synchronized clocks
may have a skew, we assign a sequence number to each checkpoint.
This sequence number is sent in all messages. If a processor
discovers that the sender has checkpointed more recently, it
creates a checkpoint. This checkpoint should be made before passing
the message up to the application -- this ensures that we remember
the message in the event of a failure, so the sender won't need to
rollback and resend.
Introduction to Logging
So far our discussion of failure and recovery has centered around
checkpointing the state of the system. The next technique we will discuss
is logging. Instead of preserving the state of the entire system at once,
we will log, or record, each change to the state of the system. These
changes are easy to identify -- we just log each message. In the
event of a failure, we will play back this log and incrementally restore
the system to its original state.
Synchronous Logging
The most intuitive technique for logging a system is synchronous
logging. Synchronous logging requires that all messages are logged
before they are passed to the application. In the event of a failure,
recovery can be achieved by playing back all of the logs. Occasional
checkpointing can allow the deletion of prior log entries.
This approach does work, but it is tremendously expensive.
Messages cannot be passed to the application, until the messages
are committed to a stable store. Stable storage is usually, much
slower than RAM, &c. Sometimes performance can be improved by
carefully managing the I/O device, e.x. using one disk for the log
file to avoid seek delays, but it is still much slower than
astable storage.
Asynchronous Logging
In order to avoid the performance penalty associated with synchronous
logging, we may choose to collect messages in RAM and to write them out
occasionally as a batch, perhaps during idle times. If we take this
approach, we have a similar management problem to that of uncoordinated
checkpoints. Some messages may be logged, while others may not be logged.
Sender-based Logging
Our examples above assumed that messages would be logged by the
receiver. Most of our discussion of logging will, in fact, be focused
on receiver-based techniques. But, before we dive into these, let's
take a quick look at logging messages at the sender.
Sender based logging is very important in those cases where receivers
are thin or unreliable. In other words, we would want to log messages
on the sender if the receiver does not have the resources to maintain
the logs, or if the receiver is likely to fail. This might be
the case, for example, if the sender is a reliable server and the
receiver a portable mobile device.
So, let's assume that each sender logs each message it sends and
that the receiver logs nothing. Recovery isn't quite so easy as
having each sender play back its logs. Although each sender can play the
messages back in the same order in which they were dispatched,
there is no way to order the messages among the senders.
One solution to this problem is to follow the following protocol:
- The sender logs the message and dispatches it.
- The receiver receives the message and ACKs it with the current
time (local to the receiver).
- The sender adds the timestamp contained in the ACK to its log
entry to the message -- the message is now fully logged
If the above protocol is followed, the timestamp can be used to
ensure that messages from multiple servers are processed by the
receiver in the proper order. This is because all of the timestamps
were assigned by the client, so clock skew is not a problem.
(The timestamp can be as simple as a receive sequence number).
But there is one small problem. Consider Sender
sending a Message to Receiver. Now consider the same Sender
sending a message, m', to Receiver. If the Receiver fails
before it ACKS m, it is unknown whether or not m was received by
the Receiver before the Sender dispatched m' -- we can't
establish whether or not a causal relationship exists.
One solution to this problem is to require that the sender send an
ACK-ACK to the receiver. If the receiver blocks until it receives
the ACK-ACK, the order of the messages will be clear.
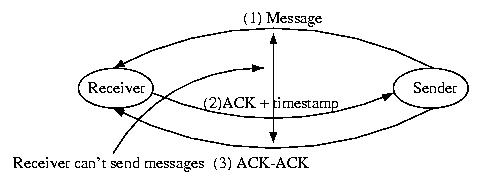
Given this protocol, recovery is very, very straight-forward. Upon
reinitialization, the failed receiver sends a message to all other hosts
in the system with the number of the last message that it remembers ACKing.
The senders then replay their logs, including the receiver-assigned sequence
numbers. The receiver applies these messages in the order of their
sequence number. The senders know to ignore the responses to these messages.
This process leads to a very simple, uncomplicated recovery.
One Approach to Recovery Using Asynchronous Logging
In order to recover from failure given asynchronous logging,
we need some way for the processors to keep track of their current
state, some way for them to communicate it to each other, and some
way of evaluating the state of the system.
The approach that we'll discuss makes use of direct dependency
vectors. Before defining a DDV, we need to define an
interval. An interval on a processor is the period of
time between receiving two messages. The intervals on a particular
processor are sequentially numbered and given an interval index.
Each time a processor sends a message, it also sends its current interval.
On the receiving process, a direct dependency vector is associated with
the event. This vector contains the processor's understanding of the
interval on all processors. This information may be out of date, and does
not take gossip into account. One processor is only informed about
another processor's interval, if it directly receives a message
from that processor. It is important to pay attention to the
fact that the interval must be directly communicated from one
process to another -- it is not transitive and cannot be communicated
indirectly. A message from processor X to processor Y only contains
X's interval, not the DDV present on X.
The diagram below illustrates the intervals and DDVs associated with
each processor.
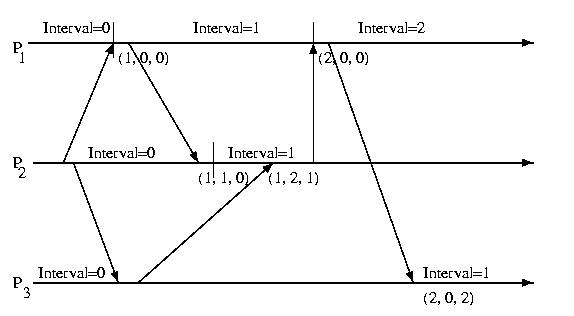
We can define the global state of the system at any point in time
to be the collection of the DDVs at each processor. We can organize
this state into a Global Dependency Matrix (GDM). We'll
follow your textbook's nomenclature and give this the somewhat
misleading label GDV.
The diagram below shows the GDV at two different points in time:
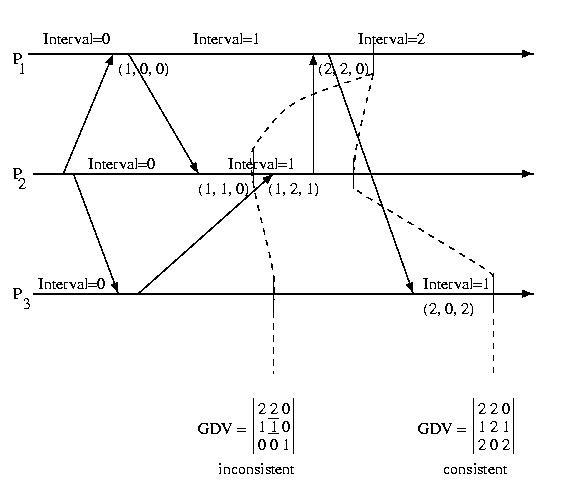
Notice that the first GDV is inconsistent. The DDV component of the GDV
from Processor 1 indicates that Processor 1 has received
a message from Processor 2 indicating that Processor 2 is in Interval 2.
But the DDV vector within the GDV from Processor 2 indicates that Processor
2 is in Interval 1. This indicates an inconsistent recovery line.
The second GDV does not have any inconsistencies -- it is consistent
recovery line.
We can check to see if a GDV is valid, by looking at each DDV one at a time.
For each entry in a consistent DDV, the interval shown for another procesor
must be less than or equal to the interval that that processor's DDV
within the GDV contains for itself.
GDV(p)[q] <= GDV(q)[q], 1<=p, q<=M
In other words, no processor can have received a message from
another processor originating in an interval in advance of that processor's
current interval.
So, we know what an inconsistent state looks like, but how do we find
a recovery line? We start out with the initial state of all processors
composing a valid recovery line. We store this in a vector, RV, that
contains the interval index for each processor -- these will initially
be 0.
Then each time a processor commits enough log entries or checkpoints
to make a new interval stable, it sends this information to a
central server that tries to advance the recovery line.
To find the recovery line, the coordinator keeps a matrix with the
current recovery line, and a bin of recent interval updates that
are are not a part of the current recovery line. The coordinator then
applies the recent update to the matrix and checks for consistency.
It also attempts to include as many of the other recent updates from
the bin as possible. If it is unable to incorporate the most recent
update into a consistent recovery lines, it adds it to the bin --
a future update may make it usable.
For those who would like a more formal look at one possible implementation
of this algorithm, the following pseudo-code might be helpful:
find_recoverable (RV, p, k)
TRV = RV // Make a copy of the current recover line (RV)
TRV[p] = k // advance the interval for processor p to k
// in this temporary copy -- a candidate
// that needs to be check for inconsistency
// Compare the DDV for each processor to the entries in TRV,
// a temporary and optimistic GDV. Record inconsistencies
// in Max
for q = 1 to M // M is the number of processors
Max[q] = max(TRV[q], DDV(p,q)[q])
// Try to resolve inconsistencies by looking at stable intervals
// that we haven't been able to use, yet (previously other
// processors weren't stable in sufficiently advanced intervals)
While there is a q such that Max[q] > TRV[q]
Let l be the minimum index such that l >= Max[q] and stable(l)
If no such l exists // if we can't fix the problem with these states
return (fail) // we're going to have to try again later to advance
TRV[q] = l // If we can fix this problem, optimistically
// add this interval to the TRV
for r = 1 to M // And recompute the Max matrix so that we
// can check for new incocnsistencies
Max[r] = max(Max[r], DDV(q,l)[r])
// There are no inconsistencies, sThere are no inconsistencies,
// so make the candidate recovery line, the real thing.
RV = TRV
return (success)
Adaptive Logging
One might observe that it isn't necessary for a processor to log
every message. It only needs to log those messages that have originated
from processors that have taken checkpoints more recently than it has.
If processors with less recent checkpoints were to fail, they would be
forced to roll back prior to the message's sending, anyway.
One approach for this problem is for each processor to give a sequence
number to its checkpoints (as we have done before), and to keep a vector
containing its best understanding of the most recent checkpoints on
all other processors.
If each time a message is sent, the current recovery line (CRL) is sent
with it, a processor can determine if it is ahead of, or behind, the
sender with respect to making checkpoints by comparing its checkpoint
sequence number, to the sequence number of the sender in CRL received with
the message. If the sender is ahead, the receiver will log the message.
If not, it won't worry about it.