Return to the lecture notes index
April 10, 2011 (Lecture 21)
Looking Ahead
Today, we are going to begin coverage of a traditional operating system
issue, but this time in a distributed environment: process allocation and
migration. We are going to ask the question, "Given many different
processors, which one do we use and when is appropriate to move to a
different one?"
But, before entering into that discussion, I would like to discuss some
preliminary concepts relavent to distributed scheduling. So, we'll begin
by looking at the economies of multiple processors, and then examine
threas, processes, and tasks in a distributed setting.
You Choose: One or N
Which is preferable, 1 processor, or N processors, each of which is
1/Nth as powerful?
In response to this question, most people point out the following
characteristics:
- Both options are equally "powerful"
- 1 processor is more likely to be completely functional than
N processors, each of which has the same likelihood of failing
as the single processor. If it is "all or nothing", this might
suggest that the single processor is more robust.
- The N processors are less likely to completely fail than the
single processor. In other words, if progress can be made with
only some of the processors, the N processors are "fail soft".
The surprising finding is this: The response time is better for a
system with one processor than N processors which are 1/Nth
as powerful. How can this be possible? Simple math shows:
N*(1/N) = 1.
Let's see if we can think our way through this situation. Let's begin
by defining response time to be the elapsed time between the
arrival of a job and the time that the last piece of the result is
produced by the processor(s). Now let's assume that there is only one
job in the system and that this job is indivisible and cannot be
parallelized. It is fair to assume that the job cannot be divided and
conquered, because any job can be reduced to a piece that is atomic.
This indivisible piece is what we will now consider.
Let's say that this job takes one unit of time in our one processor
system. If this is the case, it will take N units of time if
executed in the N processor system. The reason for this is that the
job can only make use of one processor, so it can only utilize
1/Nth of the power of the N procesor system.
Now if we assume that we have an endless stream of jobs, it might seem
like this problem goes away -- we can make use of all of the processors
concurrently. And, although this is true, it doesn't quite work out
so well in practice. As each job arrives, it must be placed on the
queue associated with one of the processors. Some queues may become
long and other queues may be empty. The backlog that builds up on
the queues that happen to be long is a penalty, whereas the unused
cycles on the available processors offer no reward.
If the arrival rate is less than the service time (which makes sense, if we
hope ever to complete all of the work), we can model the mean response
time for a system with a single processor and a single queue as below:

If you want to try to understand the formula above, you can think of
it this way. Take a look at the denominator of the equation. It
subtracts the arrival rate from the service rate. In other words, it
asks the question, "In each unit of time, if we execute all
of the jobs we have, how many jobs worth of time is left unused?"
If we have another job to submit, we must fit it into this unused time.
The question then becomes, "How many units of time does it
take for me to acquire enough left-over time to execute the new job?"
This subtraction yields the number of fractional jobs that are left
over per unit time, in this case seconds. By inverting this,
we end up with the number of units of time measured that are required
to execute the new job -- this includes the busy cycles that we spend
waiting, and those cycles used ofr the new job.
It might make sense to view this as a periodic system, where each
"unit of time" is a single period. The mean response time is the
mean case for many periods it wil take for use to find enough spare
cycles to complete our job. The piece of each period that already used
represents the cycles spent on th jobs ahead of us on the queue.
Given this, we can model the average queue length as below:

In other words, if the system is at 80% capacity,
L = (0.8/(1-0.8)) = (0.8/0.2) = 4
Again, a quick look at this can give us some intuition about why it is
true. If there are no spare cycles, the load average will be one and
the denominator will be 0, yielding an infinite expected queue length.
If the load average is 0, there are no jobs in the system, so the queue
is empty. If the load average is 80% or 0.8, we can only use 20% or 0.2
of each period for our job. This means that if our job requires 80%
of a period, we will have to wait 4 periods to acquire enough cycles,
hence an expected queue length of 4.
Given this, what happens if, instead of have one processor that has the
power of all N processors? Since it can handle N times as many jobs in the
same time, the service rate is N times greater. Since it is handling
the jobs that were previously spread out over N queues on the same queue,
the arrival rate is N times greater.
following:

Notice the surprising result: We get an N times speedup by having one
processor, instead of N processors that are each 1/Nth
as powerful!
If we service a pool of processors using a single queue, we find our
performance is somewhere in the middle. The service time is much like
having a single very powerful processor, with a single queue, except
the job take longer once it is dispatched, because the processor that
is executing it remains slower. For reference, the figure below shows
all three configurations:
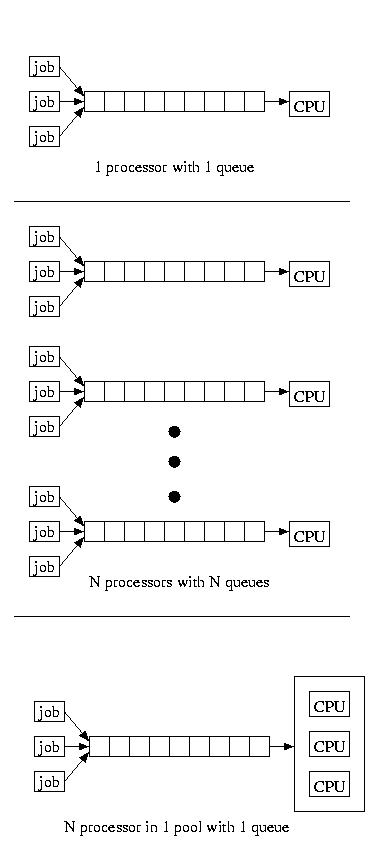
It is a good thing for us that it is cheaper to by N slower processors
than a processor N times as fast -- otherwise distributed and parallel
systems would become less interesting (at least for the purpose of
improving the response time for computationally intensive tasks).
It is also a good thing for us that, looking forward, it looks like
processors with lower clock rates, and that are otherwise a little
less able, might be able to perform significantly more work per
unit of energy input (financial and environmental cost), or heat
output (ditto). Energy efficient computing might well favor many
computers in place of a single bigger one.
So, although distributed systems might not be useful for reducing the
response times for large, indivisible tasks, they can yield more
processing power for less money, less energy, greater availabilty, and
greater accessibility for distributed user communities.
Processor Allocation and Process Migration in Distributed Systems
Our discssion is going to involve picking a processor to run a process
and moving that process from one processor to another when appropriate.
Processor allocation involves deciding which processor should be assigned
to a newly created process, and as a consequence, which system should
initially host the process.
In our discussion of process migration, we will discuss the costs of
associated with moving a process, how to decide that a process should be
migrated, how to select a new host for a process, and how to make the
resources originally located at one host available at another host.
Although these algorithms will be discussed in the context of
processes, task with only one thread, they apply almost unaltered to
tasks containing multiple threads. The reason for this is that the
interaction of the multiple threads with each other and the environment
almost certainly implies that the entire task, including all of its
threads, should be migrated whole -- just like a single-thread process.
Unlike multiprocessor computers, it only very rarely makes sense to
dispatch different threads to different processors, or to migrate
some threads but not others. In distributed systems, the cost of sharing
resources on different hosts is usually far too high to allow for
this level of independence.
An Introduction to Processor Allocation
One interesting aspect of distributed systems is that we can choose
upon which processor to dispatch a job. This decision, and the associated
action of dispatching the job onto the processor, is known as processor
allocation.
Depending on the environment, different factors may drive our decision.
For example, many environments consist largely of networks of (personal)
workstations (NOWs). In these enviornments, it may be advantageous
to "steal" cycles from other uses while they are away from their
machines leaving them idle. This is especially attractive since some
studies have shown that the typical workstation is idle approximately
70-80% of the time. Of course we would only want to do this if our
own workstation is substantially busy -- otherwise we would be paying the
price of shipping our job, and perhaps user interaction, &c, both ways
and gaining little or nothing. It is certainly forseable that the
unnecessary use of a remote processor can increase (worsen)
turnaround time.
In other cases, we may have pools of available "cycle servers" and
underpowered personal workstations. If this is the case, we can
organize our system so that it always dispatches jobs to a remote
processor. But, in either case, we want to make sure that we make
a careful choice about where we should send our work -- otherwise
some poor machine may get smashed.
Transparent processor allocation is different than simple remote
execution, as might be provided by something like rhs. The
biggest difference is in transparency -- the user need not known that
the job is executing other than locally. The second difference is that
processor allocation can lead to migration, or the movement
of a job after it has begun executing.
A Centralized Approach: Up-Down (Mutka & Livny '87)
The first technique that we'll talk about is named Up-Down. The
goal of the Up-Down approach tries to be somewhat fair to users in the
way that it allocates processors. It does this by giving light weight
users priority over "CPU hogs". Users earn points when their workstation
is idle. This is, in effect, credit for allowing others to use their
processor. Users lose points when they consume the idle CPU on remote
hosts. The points are accrued or spent at a fixed rate. This approach
assumes that a user is associated with exactly one workstation (his or
her workstation).
When a processor becomes avaialble, it gives it to the requestor with the
greatest number of points. This favors those users who are net providers
of CPU and penalizes those who are net users. In effect, it ensures that
if you only need processor time occasionally, you get it right away. But,
if you have used tons of CPU, you yield to those who have been less
demanding recently.
Obviously it is impossible for everyone to be a net consumer of CPU,
since one can't use more CPU than is available. Everyone can, however be
a net supplier of CPU, since it is possible for all hosts to be idle.
Hierarchical Approach
It requires some overhead to determine where a process should be run.
This overhead can grow quite large, especially if many machines are
assumed to be busy. An alternative to the approach described above
is to use a hierarchical approach. Instead of assuming the
peer-to-peer workstation model as we did above, we are going to assume
a model with many "worker" workstations, and a smaller number of
"manager" workstation.
We organize these workstations into a tree, with all of the workers
as leaves. The leaves are then collected into groups and each group is
given a manager. Each group of workers becomes the children of their
manager in the tree. These manager's in turn are grouped together and
given a directory. These directors have a common parent, which is the
root of the tree. One alternative is to use a "board of directors"
instead of a single root.
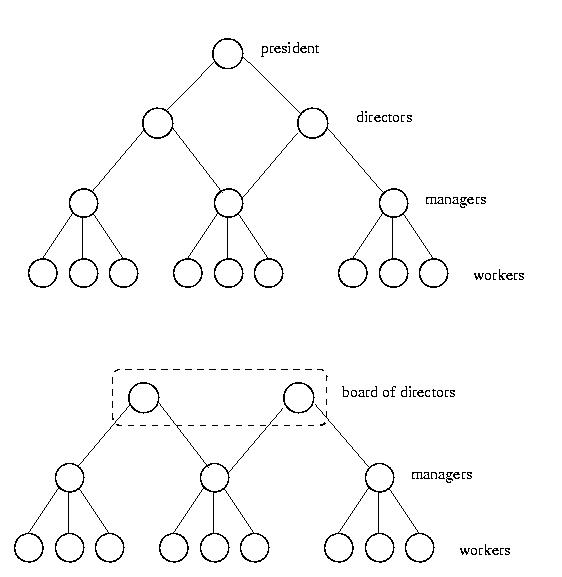
Under this organization, a worker tries to maintain its load between
a high and low watermark. If it gets too much work or too little work,
it tells its manager. Its manager will then use this information to try
to shift work among its workers to properly balance the load. The managers
themselves have quotas. If they find themelves with either a shortage or
surplus of cycles, they tell their directors, who in turn try to balance
the load among their managers, and so on. If the top level is a committee,
instead of a signle node, this provides for some level of fault tolerance.
If each member of the committee knows everything, it may be possible for
a decision to be made, even if one fails.
The goal of this approach is to reduce the amount of information that
must be communicated across the network in order to balance the load.
Let's Talk About Loads
If workstations are to cooperate and share work, they must somehow,
directly or indirectly, communicate their work levels to each other.
Obviously, this leads to a trade-off between perfect information and a
tolerable level of communication. We need to have a protocol that will
give us "good enough" information.
One nieve approach is to have processors "yell out" to everyone when
they are idle. But this approach has a big problem. If a processor
"yells out" to all of the other processors, they might all send work its
way. The previously idle processor suddenly is heavily loaded. Then,
another processor, perhaps one that recently off-loaded work becomes idle,
and "yells out". Well, that processor gets slammed with work. If a facility
for process migration exists, things get even worse. This probelem is
known as thundering herds.
In order to solve the thundering herds problem, we can use a different
form of this receiver initiated technique. Instead of broadcasting
to everyone, an idle processor can "ask around". As soon as it finds
work, it stops asking. If it doesn't find work after asking some fixed
number of hosts, it sleeps, while waiting for more of its own work,
and tries again after a dormant period, if it remains idle. This
approach leasds to hevy communications overhead when the processors
are mostly idle.
Another and complimentary approach is known as sender initiated
processor allocation. Under this approach a host which notices that its
queue of waiting jobs is above some threshold level will "ask around" for
help. If it can't find help after asking a fixed number of hosts, it
assumes that everyone is busy and waits a while before asking again.
As was the case with receiver initiated processor allocation, it is
good to poll a random collection of hosts to keep things balanced.
Unfortunately, this approach leads to heavy communications overhead when
the processors are mostly busy.
Hybrid approaches are also possible. These try to balance the costs
of the above two approaches. They only "yell out" if they are substantially
overworked or under worked. In other words, a processor won't yell out
for help, unless it has a really, really long run queue. And it won't
advertise that it has cycles available, unless it has been idle for
some time. Typically, under hybrid approaches, processors can operate
in both sender-initiated or receiver-initiated modes, as necessary.
Processor Allocation and IPC
When processors are interconnected with each other via IPC, this becomes
a consideration for processor allocation. If the processes are cooperating
very heavily and cannot make progress without IPC, it might make sense
to run them in parallel. Co-scheduling (Ousterhout '82) is
one technique for resolving this. It schedules groups of cooperating
processes to run in parallel, by useing round-robin style scheduling,
and placing the cooperating processes in corresponding time slots
on different processors.
Another technique, known as Graph Theoretic Deterministic
scheduling builds a weighted graph of all of the processes. The edges
are IPC channels, weighted by the amount of communication. The basic idea
is that it is best to have processes that require a great deal of IPC
running on the same host, so that the latency associated with the IPC
is minimized. These approaches work by partioning the graph into one
subgraph for each processor in such a way as to minimize the weight of
the disected edges.
Although the complexity of these approaches makes them poor choices for
real-world systems, they are a rich area of theoretic research. It is
also common place for humans to keep IPC vs. network traffic in mind
when making this type fo decision by hand.
A Microeconomic Approach
I have to confess that this approach, Ferguson, et al, in 1988, isn't
the most practical, and it isn't of much theoretical significance --
but I love the free market. I can't help myself.
The basic idea is that processes are given money, perhaps in accordance
with their priority. They take this money and buy the resources that
they need, including a processor and the communication channels to
move there and back.
When a processor becomes available, it holds a bid. The high bidder wins.
Processes bid for a processor by checking a bulletin board to see what
the processor's last selling price was. They also consider the cost
of the network connection to move there and back. Once they've done
that, they decide which processors they might be able to afford, and
make a bid on one them. They bid on the processor that wil give them
the best service (fastest clock?), while leaving them with enough
of a surplus that they can still afford to get back, if the communication
channel goes up in price.
They bid the last winning bid, plus a piece of the surplus that would be
left over if they won the bid. This surplus is what's left over after the
processor wins the bid and buys the network, &c. The surplus is important,
because the network could go up in price -- the surplus may prevent
the process from becoming stranded for a long time.
This approach isn't very practical -- it requires a great deal of overhead.
And it isn't clear to me how money should actually be handed out. But
it does provide an efficient use of resources. It might also be useful
in cases where resources can provide distinctly different qualities of
services. In these cases, the free market system might ensure that they
are allocated in an efficient way. Of course, the efficiency would have
to be sufficient to justify the very high overhead of this technique
-- not likely.
Process Migration and Virtual Machines
If you've got a virtual machines and a distributed file system, you've
saved some problems. The VM can migrate, moving the file sessions and
internal state with it. But, depending on the VM configuration, it might
or might not be able to keep its old IP address.
To keep its old IP address, it has to be a public IP address assigned to
it, rather than a situation where it gets a private IP address within a
VPN and publicly uses the public IP of the host. It also has to migrate
within the same network, so broadcasts to its MAC address still get there.
And, lastly, switches and the like need to be made aware of the move,
so they don't misunderstand where it is in a bridged link layer and
deliver its messages to the wrong leg.
VMs really can help to make migration almost transparent, especially if
there exists a DFS that won't become confused by the move and the
file interaction is structured as open-read/write-close transactions. But,
that brings us to the hard part -- it is the external (network) interaction
that is the hard part. And, VMs really can't fix this.
What's The Answer?
To the extent that we can use virtual machines to abstract away the problem,
that is fantastic. They might or might not be an option for reasons of
efficiency, compatibility, etc. But, to the extent that they are an answer,
they are often a nice, clean one.
Beyond that, we've got to hide the migration within lower-level primitives.
For example, we don't want our code to be filed with hacks to handle
migrating TCP connections. Instead, we want to build a recoverable,
migratable communications layer: one that can suspend, update, and resume.
This way, our program logic is clean -- and our communications layer can
hide the dirt.