Return to lecture notes index
August 28, 2014 (Lecture 2)
The Area We Call "Systems" -- And the Funny Creatures We Call "Systems People"
When I'm hanging out in the "Real world", people often ask me about my job.
I usually explain that I am a teacher. Everyone understands what a teacher
does. We talk for a living. Beyond that, I'm safe. Everyone knows, "Those
who can, do. Those who can't, teach."
When people ask me what I teach, I tell them, "Computer Science". Oddly
enough, they only hear the first word, "Computer". Sorry, ya'll, I don't do
windows. You'll need IT for that. This brings me to two questions,
"What is the area we call, Comptuer Systems?" and, "How does Distributed
Systems fit in?"
When I explain my area of interest to every day folks, I like to tell them
that in "Systems" we view the computing landscape as if it were the air
traffic system or the system of highways and roadways. There is a bunch
of work that needs to get done, a bunch of resources that need to be used
to get it done, and a whole lot of management to make it work.
And, like aur and auto traffic, computer systems is most interesting
when it scales to reach scarcity and when bad things happen. We care
about how our roadways and airways perform during rush hour, in the rain,
when there is a big game, and, by the way, bad things happen to
otherwise good drivers along the way. In otherwords, our problem space
is characterized by scarcity, failure, interaction, and scale.
Distributed Systems, In Particular
"Systems people" come in all shapes and sizes. They are interested in such
problems as operating systems, networks, databases, and distributed systems.
This semester, we are focusing mostly on "Distributed systems", though
we'll touch on some areas of networks, and monolithic databases and
operating systems.
Distributed systems occur when the execution of user work involved
managing state which is connected somewhat weakly. In other words,
distributed systems generally involve organizing resources connected
via a network that has more latency, less bandwidth, and/or a higher
error rate than can be safely ignored.
This is a different class of problems, for example, than when the limiting
factors might include processing, storage, memory, or other units of work.
There is tremendous complexity in scheduling process to make efficient use
of scarce processors, managing virtual memory, or processing information
from large attached data stores, as might occur in monolithic operating
systems or databases. It is also a different class of problems than
managing the fabric, itself, as is the case with networks.
Exploring the Model
When I've taught Operating Systems, I've begun with a picture
that looks like the one below. If you didn't take OS, please don't
worry -- everything on the picture, almost, should be familiar to
you. It contains the insides of a computer: memory and memory
controllers, storage devices and their controllers, processors, and
the bus that ties them all together.
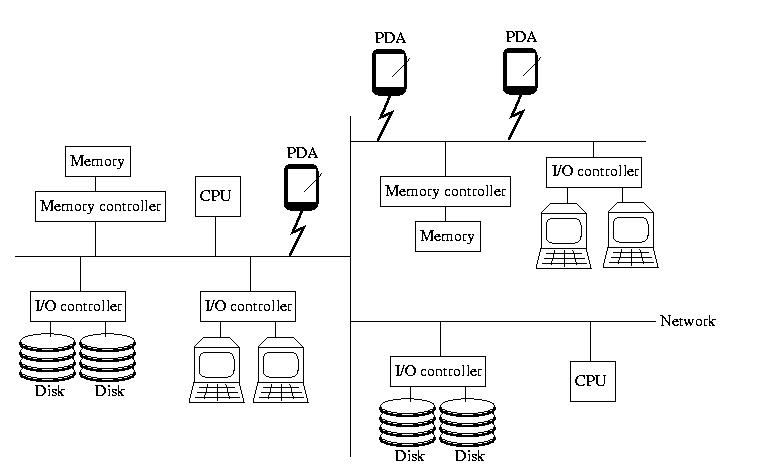
This time however, the bus isn't magical. It isn't a fast, reliable,
predictable communication channel called that always works and maintains
a low latency and high bandwidth. Instead, it is a simple, cheap,
far-reaching commodity network that may become slow and bogged down
and/or lose things outright. It might become partitions. And, it might
not deliver messages in the same order that they were sent.
To reinforce the idea that this is a commodity network, like the
Internet, I added a few smartphones to the picture this time. Remember,
the network isn't necessarily wired -- and all of the components
aren't necessarily of the same type.
Furthermore, there is no global clock or hardware support for
synchronization. And, to make things worse, thr processors aren't
necessarily reliable, and nor is the RAM or anything else. For
those that are familiar with them, snoopy caches aren't practical,
either.
In other words, all of the components are independent, unreliable
devices connected by an unreliable, slow, narrow, and disorganized
network.
What's the Good News?
The bottom line is that, despite the failure, uncertainty, and
lack of specialized hardware support, we can build and effectively
use systems that are an order of magnitude more powerful. In fact we can
do this while providing a more available, more robust, more convenient
solution. This semester, we'll learn how.
Distributed Systems vs. Parallel Systems
Often we hear the terms "Distributed System" and "Parallel System."
What is the difference?
Not a whole lot and a tremendous amount -- all at the same time.
"Distributed System" often refers to a systems that is to be used by
multiple (distributed) users. "Parallel System" often has the connotation
of a system that is designed to have only a single user or user process.
Along the same lines, we often hear about "Parallel Systems" for
scientific applications, but "Distributed Systems" in e-commerce or
business applications.
"Distributed Systems" generally refer to a cooperative work environment,
whereas "Parallel Systems" typically refer to an environment designed to
provide the maximum parallelization and speed-up for a single task.
But from a technology perspective, there is very little distinction.
Does that suggest that they are the same? Well, not exactly. There are
some differences. Security, for example, is much more of a concern in
"Distributed Systems" than in "Parallel Systems". If the only goal of
a super computer is to rapidly solve a complex task, it can be locked
in a secure facility, physically and logically inaccessible -- security
problem solved. This is not an option, for example, in the design of
a distributed database for e-commerce. By its very nature, this system
must be accessible to the real world -- and as a consequence must
be designed with security in mind.
A Brief History
Distributed Systems, as we know them and love them, trace their origins
to the early 1980s. Or, if you'd like to dig a little deeper, the 1970s
(DECnet, SNA, DSA, and friends). We didn't have global scale computing
in the 1970s and 19802, but we did have enterprise-level computing,
networking existed (Ethernet was invested in 1973), computers were being
clustered locally for performance and scale, and personal computing was
arriving. It was clear that computers were becoming smaller scale, lower
cost, and more ubiquitous. And, it was apparent that networks were becoming
faster, wider, and cheaper.
To oversimplify things a bit, this led to the question, "Can we build a
global (or, at least, super large) scale distributed computer?" And, loosely
speaking, much of the distributed systems work done from the early 1980s
through the early 1990s was centered around the goal of managing resources
at this scale trhough what can (again, taking some liberties) be described
as "The Great Distributed Operating System In The Sky."
The goal was to invent a software management layer that enabled users to
harness the distributed resources (processing, memory, storage, users, etc)
just like a normal operating system does for the recources within a
single computer. The goal was to make the distributed nature of the
resources "transparent" to the user, such that the user didn't have to
know or care that the resources were distributed, despite the limitations
of scale and communications.
A lot of good things came out of that era. CMU's Andrew project effectively
invented distributed file systems and the techniques that are nearly
universal today for implementing them. MIT's Project Athena practically
invented modern authentication in the form of Kerberos, which remains
in use today. Distributed transactions, replication schemes, etc, etc, etc
were all children of this era.
But, it all came to a crashing end in the early 1990s. The dream of
"The Great Distributed Operating System In The Sky" was not, and is not,
to be. The bottom line is this: We can't have a general purpose distributed
shared memory, because the communication required to build one is too
expensive. We'll take about it shortly, when we talk about "atomic
commit protocols".
But, one way to think of it is this. At the most primitive level, we
normally enforce mutual exlusion and other synchronization via shared
memory. But, in distributed systems, we need synchronization to construct
a consistent shared memory. Chicken or egg?
For a while we looked at "relaxing" the memory model to meet most needs
in an efficient way -- but that didn't really work. So, by the early
1990s, this phase was over. Instead, the focus became "Middleware" --
using specific software layers to construct specific solutions to specific
classes of problems, rather than trying to make one size fit all.
Distributed systems research died down for a while. Then it got red-hot
with the "Dot Com Boom of the late 90s and early 2000s". As Internet-based
commerce exploded, infrastructure needed to be distributed to scale up,
ensure robustness -- and meet the needs of users distributed around the
globe. Then, the dramatic growth and increasing value of data generated a
focus on "Data Intensive Scalable Computing (DISC)", i.e. the scaling
of the processing of data.
And, this growth continues to be fueled by ubiquitous computing in the form
of mobile devices, "The Internet of Things", the back-end infrastructure
needed to support this, energy-aware computing, and more. It is an exciting
time to study distributed systems!
Abstraction
We'll hear about many abstractions this semester -- we'll spend a great
deal of time discussing various abstractions and how to model them in
software. So what is an abstraction?
An abstraction is a representation of something that incorporates the
essential or relevent properties, while neglecting the irrelevant details.
Throughout this semester, we'll often consider something that exists in the
real world and then distill it to those properties that areof concern to us.
We'll often then take those properties and represent them as data structures
and algorithms that that represent the "real world" items within our software
systems.
Traditional Tasks, Processes, Threads, and Threads of Control
Computer systems exist to accomplish work, right? Unless they accomplish
something, they aren't worth much, are they? For this reason, one of the
most fundamental abstractions we have in a computer system is the one that
represents user work. Depending upon the details, this abstraction might
be known as a Process, Task, or Thread (or even
Transaction, etc, etc, etc).
In operating systems, the basic abstraction for user work is the
process. Think back to 213 -- remember fork()ing to create them,
wait()ing for them to end, etc? Remember the state associated with a
process? Things like the page tables and pages of memory; memory area list;
signal masks, flags and handlers; file descriptors; registers, etc. By
keeping track of this state, often within a struct called the Process
Control Block (PCB), the operating system can keep track of and manage
user work.
Also remember our friend the thread, which was like a baby process.
It had its own stack and registers, but basically shard many of the
other resources with other threads assocaited with the same process. In
some systems, thread state is maintained via a Thread Control Block
(TCB).
Some people, and some operating systems refer to processes that are, or can
be, assocaited with multiple threads as tasks, in which case the
equivalent of the PCB might be called the task_struct. Or, for example,
in Linux, when they added threads, they essentially kept the old PCBs, but
essentially used them as TCBs, by having them point to shared copies of
shared resources, such as page tables and file descriptor arrays, and created
a task_struct that was just a thin veneer to point to identify the related
PCBs, etc.
Tasks in Distributed Systems
In distributed systems, we find that the various resources needed to
perform a task are scattered across a network. This blurs the distinction
between a process and a task and, for that matter, a task and a thread.
In the context of distributed systems, a process and a thread
are interchangable terms -- they represent something that the user wants
done.
But, if we back up far enough, task can have an interesting and
slightly nuianced meaning. A task can be seen as the collection
of resources configured to solve a particular problem. A task contains
not only the open files and communication channels -- but also the
threads (a.k.a. processes). Distributed Systems people often see a task
as the environment in which work is done -- and the thread or process as
the instance of that work, in progress.
I like to explain that a task is a factory -- all of the means of production
scattered across many assembly lines. The task contains the machinery and
the supplies -- as well the processes that are ongoing and making use of them.
Migrating Computation
In order to migrate computation, we need to do more that migrate the
in-progress computation. We need to move or replace the resources it is
using, for example, memory and files. And, worse than that, we have
to migrate the state of the interaction with the resources. For example,
if we move a process-in-execution from one host computer to another,
things won't go well if the file it is using to get data isn't there.
And, beyond that, even if the file is there, things might not go well
if we haven't preserved the state of our interaction with that file,
e.g. the association with a file descriptor, the position within the file,
the file mode, etc. Distributed file systems, for example, might
make the file availabel across the ecosystem -- but we may have to
construct our own abstraction for transactional I/O or recoverable file
sessions.
Communication is even more complex. Imagine, for example, a process
that receives requests over the network. If it moves to another host,
the communication session is broken. And, worse, there is nothing
that the process, or even the process's host, can do to fix the problem
-- the other side of the communications channel needs to learn about
the process's new location and/or a relay needs to be left behind to
forward messages.
Migrating File State
Imagine moving a process that is using files. You move the process,
and the file is available, perhaps because of a distributed file system
such as AFS. But now what? Well, there is probably a global state
problem. The new host operating system knows nothing about this process's
use of the file. The file needs to be reopened, and any needed state,
such as the session's mode (read, write, both, etc) and the file offset
need to be restored.
This isn't terrible. Essentially, we can keep track of the essential
file state within the process and be ready to recreate it, if needed.
In a simple model, the migration system guarantees that higher-level
file operations are atomic, and each such operation opens the file,
seeks as needed, performs a read or write, and then closes the file.
A more sophisticated model might maintain the same file state, but only
reopen the file when needed. Instead, the migration framework closes the
file upon migration. The higher-level file operation check the state
of the file descriptor. If it is valid -- it uses it. If not -- it
reopens it. In this model, the close() operation remains a part of the
interface, but only closes the file if it hasn't already been closed
by a migration.
If a distributed file system isn't available, then the reopening of
the file might involve copying it from another location, as by scp,
rsync, or HTTP, etc.
This is only one model -- there are certainly plenty of others. The real
goal here is to think about the state associated with the file session,
to realize the challenge, and to realize that there are options for
solving the problem.
Migrating Communication Sessions
Migrating processes that are involved in communication is in many ways
more invovled than migrating processes wiht files. As with files, it
isn't good enough to migrate just the process state -- we also need
to reestablish and map gloabl state, such as network sockets.
But, it gets trickier from there. What about the other side? Unfortunately,
we tend to name network resources, at least in part, by their location on
the network, e.g. <IP address, port number>. Given this, when
a process has moved -- it has lost its common name. At some level, the
answer here is easy. Much like we needed a higher level file abstraction
-- we need a higher level network name.
But, there is an old saying in distributed systems, "It is easier to
move a problem than it is to solve it." So, let's imagine a higher
level abstract name. We still need a way to convert this name into
a location on the network to which we can actually send a message.
And, we need to deal with annoying edge cases, such as what happens
when a process move mid-transmission.
One solution to this problem is to handle migration in phases. First,
temporarily stop establishing new connections -- allow them to be queued
at the sender or elsewhere. Second, allow the pipeline of
messages-in-flight to arrive. third, migrate the process. Fourth,
tell those who need to know the new host location. Fifth, re-establish
communication.
Who should be told about the new mapping from ID to location? Well, this
depends upon the model. Perhaps, it is broadcast to all possible
participants. Perhaps it is sent to those with interrupted sessions as
part of an invitation to resume. Perhaps those who have stale informtion
or no information at all will be allowed to fail -- and then to recover
by periodically broadcasting a request for an update until receiving one
or timing out. Or, perhaps there is a directory server, similar
to Dynamic Domain Name Server (DDNS) for hosts, that is
kept up-to-date by a migrating process or a coordinator, and is able
to act as the white pages, proving up-to-date information to requesting
hosts. Such as white pages might have a few possible replies:
unknown process, the correct location, or a hint that migration is in
progress and the request should be made again soon.
by the migrated process
And, of course, plenty of other models are possible. The basic idea
here is that communication is messy -- but can be managed. It involves
not only process state and local host state, but also state on the
communicating host. And, even worse, it is complicated by the need to
maintain names that aren't location based, and to keep them up-to-date and
by the possibility of messages-in-flight during a migration. It can be
managed by creating transitional states to allow for the draining and
restarting of the pipe, creating higher-level names, and proving
central (think DDNS-like) and/or distributed (think polling and broadcast)
solutions for maintaining name-location mappings, as needed.