Return to the Lecture Notes Index
Lecture 5 (January 26, 2000)
Many thanks to Jason Flinn for his contribution to today's notes. -GMK
Preemptive SJF
Review
A preemptive of SJF would allow the scheduling decision of a process
to be re-evaluated based on new jobs that have arrived or based on the
quality of the estimate. If a shorter job arived, it could be run. Or if
the estimate proved to be inaccurate, and the expected completion time
increased, another job might be selected to run. In this way, it
preemptive SJF is a dynamic approach.
I/O and CPU bound jobs might be mixed to try to keep all of the I/O
devices busy. Estimates could be made of the CPU/IO burst cycle of the
processes and they could be scheduled accordingly. These estimates can
be adjusted based on past experience using averaging:
Estimating CPU Time
T(1) = T(0) * alpha + C(1) * (1-alpha)
0 <= alpha <= 1
C = measure of CPU time that was used during a time quantum.
T = running average.
Strategies
- Favoring processes with short CPU bursts is equivalent to
favoring I/O bound processes (and vice-versa).
- One approach might be to increase a processes' priority when
it completes I/O and to decrease it when it consumes too much
CPU (to prevent the priority from constantly growing).
- Another approach might be to boost the priorities of processes that
have been on the ready queue for a long time.
- Real systems have lots of tweeks.
- Malicious users can game the system if they know the scheme.
Round-Robin Scheduling
In many ways, round-robin is like a preemptive FIFO. Each process
runs for some, fixed amount of time before the scheduler is reinvoked.
This time period is called a quantum or time slice.
When the sceduler is reinvoked, the next process in line is run. The
"line" is the ready queue (obviously, blocked processes, &c can't run).
Context-switches may occur because the process's quantum has expired,
or for some other reason (ex. I/O operation). So it is possible for
processes to receive fractional part of their quantum.
Multi-level Queue Scheduling
Multi-level queue scheduling works by dividing processes into
different classes and giving each class its own ready queue.
Different scheduling policies might be enforced on each queue. That is
to say that one class of jobs might be managed with SJF and another with
FIFO, and another with Round robin.
Examples of process classes might inclue the following:
- system processes
- interactive processes
- background processes
- batch processes
But how do we divide the CPU among the different queues (one for
each class)? We could give an absolute fraction of the CPU time to
each class, or assign a different priority to each class. Other
techniques have also been employed.
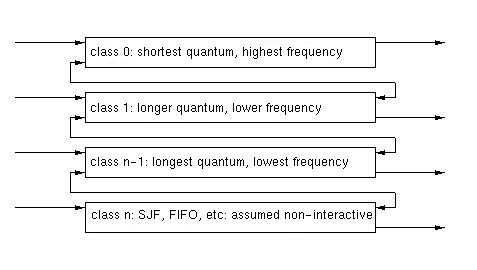
Multi-level Feedback Queue Scheduling
It would be nice to dynamically move processes between classes. We
can do this by looking at a program's behavior.
We can start each processes in a default class (class 0), and watch its
behavior. If the process doesn't finished before its time quantum expires
(context switch), we move it down a level. Each successive level has
a longer quantum, but a lower priority. The idea is that the I/O bound
proceses with short CPU bursts should be sceduled first, since this
does the best job of overlapping CPU and I/O to make the most complete
use of the system.
The last class is scheduled SJF, FIFO, or in some other non-timesharing
way. The hypothesis is that jobs that reach this class are not interactive.
Perhaps there should be some mechanism to move jobs back up, but this
is not part of the classical definition of this approach.
Digression: Round Robin and the Time Quantum
As the time quantum used with the round-robin policy approaches 0,
the overhead approaches infinity. But if overhead were not an
issue, round robin would produce perfect sharing. It would appear
to each proces that they had their own, be it slower, CPU -- execution
would be very consistent. (But this is much like building a 0-friction
perpetual motion machine).
If an infinite time quantum is used with round-robin, the policy
becomes, in effect, non-preemptive first-come first-served.
Process Synchronization
Consider the following threads executing concurrently.
| thread 1 |
thread 2 |
| x=x+1 |
x=x+2 |
| (x is global) |
The code above can be better understod by considering it in a lower-level,
more assembly language-like form:
| thread 1 |
thread 2 |
| load register from x |
load register from x |
| add 1 to register |
add 2 to register |
| store register to x |
store register to x |
Imagine that evil observer can cause context-switch to happen when
a context-switch is most painful.
One possible execution sequence might be the following:
| thread 1 |
thread 2 |
| load register from x |
|
| |
load register from x |
| |
add 2 to register |
| add 1 to register |
|
| store register to x |
|
| |
store register to x |
now x is 2 (could also be 1 or the expected value of 3).
This is called a race condition. A race condition occurs when the
output of the program is depends on the sceduling sequence of the threads
or processes.
Code segments that manipulate common global variables are called critical
sections. Critical sections that involve the same shared date/resource
cannot be interleaved by the scheduler without risking corruption of the
shared data/resource.
We need mutual exclusion between threads which play with the
same global variables.
The Bounded Buffer Problems
One classic type of mutual exclusion problem is the bounded buffer
problem. This type of problem is characterized by the following:
- a shared, circular buffer with a capacity of n items
- a producer putting items into the buffer
- a consumer taking items out of the buffer
- the goal of ensuring that the producer stops if the buffer is full
- the goal of ensuring that the consumer stops if the buffer is empty
Consider the example below, where the buffer is augmented with the
following:
- in - pointer to slot where next item will be inserted.
- out - pointer to slot where next item will not read from.
- count - number of items in the buffer.
producer
{
while (1) {
produce item;
while (count == N);
buffer[in] = item;
in = (in+1)%N;
count++;
}
}
consumer
{ while (1) {
while (count == 0);
take item from buffer[out];
out = (out+1)%N;
count--;
}
}
For this to work correctly, we must protect the critical sections to
ensure mutual exclusion. We can view the structure of this problem
as follows:
while (1) {
enter section
critical section
exit section
remainder section
}
The remainder section represents the portion of the code that is
not part of the critical section.
Somehow, the enter section needs to mark status before entering
critical section, so that no other process/thread will enter.
Then exit section needs to unmark the status, allowing another access.
What does it mean for solution to be correct?
There are three required characteristics of correct solutions to the
mutual exclusion problem.
- mutual exclusion: only one thread at a time can be in the
critical section.
- progress: if some thread wants to enter the CS, and
no other threads are in the CS, then only threads in the
entry or exit section can affect the thread's ability to
enter the CS. Decision of which thread should enter the
CS should not be delayed indefinitely.
- bounded waiting: if a thread wants to enter the CS,
and has begun executing the entry section, then it must
not be possible that infinitely often other threads enter
and leave the CS (without the thread entering the CS).
Correct solutions also must assume that all threads execute at non-zero,
but unknown speed.
Implementing Synchronization
We'll assume that basic memory accesses are atomic and that they are
aligned on address that is multiple of the word size (8, 16, 32, or 64 bits, depending on the machine).
Now, let's consider two threads (thread 0 and thread 1).
We'll take a look at some potential solutions. The solutions below are
for thread i. The other thread will be thread (i-1).
| Broken Solution #1 |
|---|
int turn = 0;
Entry: while (turn != i);
Exit: turn = 1-i;
|
|
This solution does guarantee mutual exclusion, since it is impossible
for both threads to be within the critical section at the same time.
Unfortunately, it does not guarantee progress. This is because it
strictly requires alternation into and out of the critical secion
among the threads -- even if one thread does not need the critical
section.
Consider the problems that this might cause if one thread frequently
entered the critical secion and the other only needed it once during
their lifetime. Or worse -- what happens if one thread exits before the
other -- the remaining thread has at best one last shot at the critical
region, before it is forever blocked.
|
| Broken Solution #2 |
|---|
int flag[2] = {false, flase}
Entry: while (flag[i-1]);
flag[i] = true;
Exit: flag[i] = false;
|
|
The idea here is that we use a flag to indicate whether or not
the critical section is needed. This way if one thread does not need
the critical section, and it is available, the other can enter immediately
-- without waiting for an alternating turn.
While this approach may be more fair, it is also broken. It does not
guarantee mutual exclusion. The problem here is that the testing and
the setting of the flag variable are not atomic. One thread could
test the state of the flag variable (the while condition) and then
be preempted. The other thread could do the same thing. Now both
threads are free to move into the critical section -- violating mutual
exclusion.
|
| Broken Solution #3 |
|---|
int flag[2] = {false, false}
Entry: flag[i] = true;
while (flag[i-1]);
Exit: flag[i] = false;
|
|
No problem. If we reverse the test (while condition) and the set
(flag[i] = true), we can fix the mutual exclusion problem. It is now
impossible for both processes to enter the critical section at the same
time.
Unfortunately, this approach creates a problem of its own -- deadlock.
Since the test and the set are still not atomic, it is possible for
both processes to set their flag, before either can enter the critical
section. At this point, neither process will ever be able to execute,
because each is waiting for the other -- this is deadlock.
In this case, this can happen if one process sets its flag and is preempted,
and then the other process sets its flag and is preempted. Now, when either
process is scheduled, it will wait for the other.
Actually, this situation is most likely to occur on a multiprocessor system,
where scheduling isn't the only issue. The two threads could be executing
concurrently on two different processors and find themselves in the same
position.
|
| Broken Solution #4 |
|---|
int flag[2] = {false, false}
Entry: flag[i] = true;
while (flag[i-1]) {
flag[i] = false;
wait for some time;
flag[i] = true;
}
Exit: flag[i] = false;
|
|
We could try unsetting the flag, waiting for a while, and trying
again...perhaps this would break the deadlock?
Not really. This just makes the deadlock worse. Now we are in a
livelock a special case of deadlock, where we are burning
cycles doing absolutely nothing. With the exception of the wasted
"wait for some time" this solution is equivalent to Broken
Solution #3.
|