Return to the Lecture Notes Index
Lecture 4 (January 24, 2000)
Reading
Chapters 5 & 6
The Process Control Block (PCB)
We've already discussed several different types of hardware state that
are associated with a process. In addition to the hardware-context, there
is also the software-context of the process. This includes the state of
the programs memory as well as the information that the operating systems
maintains about each process. This information is stored in an operating
system structure called the process control block (pcb). Among other
things, the PCB contains the following:
-
The process ID of the process - a unique number that identifies
or names the process within the operating system
-
The group ID - a number that identifies the group or classification of
users to which the process belongs.
-
Information about open files
-
Accounting information (CPU time used, bytes read/written, &c)
-
Current state (BLOCKED, READY, RUNNING) (more later)
-
Linked lists and queue pointers (more later)
-
Exit status that is maintained for wait (more later)
Student Question: Does the PCB maintain scheduling information?
Answer: Yes. It contains the process state, and perhaps accounting
information that will affect its scheduling priority. We'll talk more about
scheduling soon.
Process State Diagram
You saw this diagram last class:
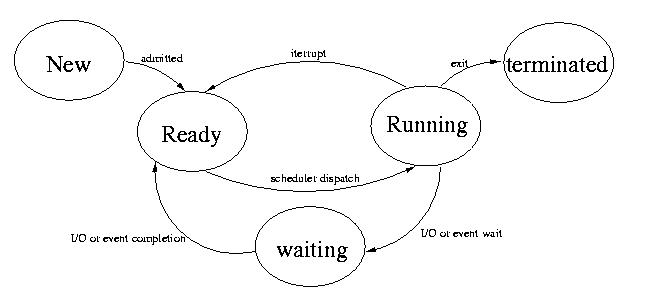
When a process exits, most of the process's resources are deleted.
But the exit status is maintained in the PCB until the parent picks up
the status and deletes the PCB. A process is said to be a zombie,
if the parent dies before it does. In this case, the init process will
wait for the child and delete the PCB.
There is a global variable, active, that keeps track of which
process is currently running.
The Ready Queue
In most systems there is only one process, in others there are several
procressors. In general, we assume that there can be many more processes
that are ready to run than can actually run at any point in time.
For this reason, we maintain a queue of ready processes. Our favorite
way of implementing a queue is with a doubly linked list. But there many
different ways. In class, for simplicity, We'll just draw queues as singly
linked lists.
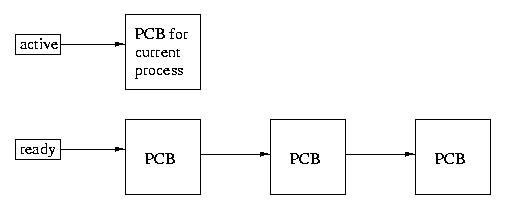
One simple scheduling disciple involves selecting the active
process by moving back and forth, round robin, through the ready list.
Each process is selected, in turn, to become the active process.
More about scheduling soon.
The Blocked Queue
Generically, we can view the blocked state as consisting of a single
blocked queue, containing all processes that are blocked -- regardless
of the reason. But actual systems implement a separate queue for each reason.
For example, there is a separate queue for each terminal device, a separate
queue for each process's inbound IPC, and a separate queue for each process's
inbound IPC communications.
Lots of Pointers
More sophisticated systems might have multiple ready queues in addition
ot the multiple wait queues. Different ready queues could be used to contain
different types of ready processes.
It is also difficult to find the PCB from a PID, since there are many
queues to search.
The PCB for a process can actually be in multiple queues at the same
time.
The consequence is that real operating systems have lots of ugly pointers
to implement these interconnected queues and other data structures. We'll
draw them separately and neatly, but that is only so that the examples
are clear.
Switching Contexts
Schedulers often change the running process. This is process requires
a context switch. As you might conclude by considering the amount
of process-state that must be saved and restored, this is a very expensive
process.
So why would an operating system want to context switch?
-
Allow one proces to run while another is waiting for I/O
-
One process exits or otherwise terminates
-
The OS wants to preempt a process to allow another process to run
-
The OS wants to give a newly created process priority
-
&c
Context switches can only occur in kernel mode. This is because the lists,
queues, and other resources that must be affected during a context switch
must alos be protected.
The good news is that any time we might want to perform a context switch,
we are already in kernel mode:
-
Interrupts signalling a change in an I/O device
-
Timer interrupts
-
System calls
...each of these events (and many more) cause entry into the kernel mode.
The Idle Process
What happens when there are no user or system processes to run? Perhaps
there is no useful work to do, or all of the useful work is blocked for
various reasons.
Most systems run a special process called the idle process.
Rhetorical Question: So, what can the idle process do?
Student answer: Crack MP3.
Instructor Answer: While this might be a useful thing, we actually
can't do this. This could be run as low priority process. By defintion,
the idle process only runs when nothing else can run.
The semantics of this process are very simple:
x GOTO x
Since the purpose of this process is to occupy an idle CPU, when absolutely
nothing else can fill that role, it is critical that this process can never
block. And since this process achieves absolutely no useful work, it is
critical that it not occupy the CPU when anything else can run.
If we look at the semantics of the process (x GOTO x), it should be
fairly easy to convince ourselves that this process can't block.
Student Question: It looks like the only way out of this process
is via an interrupt? But there's nothing happening, so one won't occur.
And the program doesn't end. How do we get out?
Answer: We don't want to get out until a new process is created
and is runnable or an existing process is unblocked. Either requires that
an interrupt is generated by an I/O device. The handler for the interrupt
gets us out of the idle process and allows the scheduler to run.
Student Question: Can't we perform system maintenance?
Answer: Perhaps, but this cannot replace the idle process, because
system maintenance processes can block. And the idle process must not block
-- the CPU is running, so it must do something. This type of task can be
run with a very low priority, so that the only thing with a lower priority
is the idle process. The only other option is to hard-code the scheduler
to handle the special case of no runnable processes -- the idle process
is a much cleaner fix.
Student Question: Can't we do better? Is there really nothing
better?
Answer: No, we can't do anything else -- never mind anything
better. This is the universal requirement for the idle process to run.
Anything useful might block.
Student Question: What about powering down?
Answer: This is the modern approach. Many systems do reduce power
by slowing down the CPU. The idle process still loops -- just more slowly.
When something else can run, the CPU speed is restored. Some processors
can power down and wake-up when an interrupt occurs.
Student Question: What about polling I/O devices? Don't these
want to poll while idle is running?
Answer:
Modern systems don't actually implement or allow polling. Although
a program might poll a device, the program is actually polling the software
maintained state of the device. This state is actually maintained using
interrupts. Consider the software instruction
ioctl (fd, FIONREAD, &count)
A program can use this to poll a device. it returns the number of characters
ready to read. But the infomration accessed by this call is maintained
via interrupts. The kernel never busy-waits; this is very inefficient.
There are some very infrequent periodic events that might occur on the
order of ever 100mS. But this is very different -- the period is very wide
and it isn't really polling.
The other thing is that the idle proces might run 99.9% of the time
or it might not run for weeks. There are no guarantees. Polling in the
idle process is certainly not safe.
Although the need for the idle process could be obviated by a special case
in the scedule, this would mean not only special-case code, but also that
the sceduler would need to be interruptable. The idle process is a better
solution in the OS, because as with other software, it avoids a nasty special
case.
It can be implemented as a regular process with the lowest priority
(reserved for idle), or with very simple special case code to ensure that
no process is every added behind it in the ready queue.
Student Question: The book talks about process aging. Won't this
eventually force the idle process to run, even though other process are
ready?
Answer: The books speaks of aging processes. This means raising
their priority over time to avoid starvation, regardless of the other facets
of the scheduling discipline. If aging is used, the idle process is a special
case -- it should not be aged.
Threads, a.k.a Light-Weight Processes (LWP)
Threads and light-weight processes are, in the context of operating
systems, the same thing. Some vendors may assign special meanings to these
terms, but this is vendor-specific.
Consider the state of a process: PCB, memory, registers, &c.
Now suppose that we want multiple process-like things that are separately
schedulable -- but share memory.
Our model of processes and the OS currently looks like this:
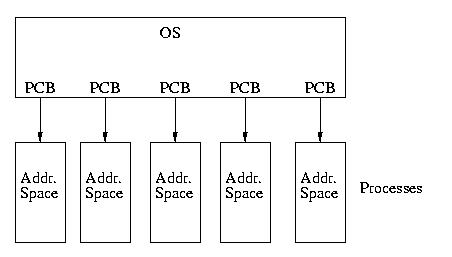
Now consider multiple "processes" sharing the same memory, but otherwise
maintaining different state (registers, &c). We call these processes
within procesees threads. We call them this, because they are separate
threads of control within the same process (actually, there is a
slightly different term for this, but we won't introduce it).
Instructor Question: Why would we want this? Why not just have
separate address spaces?
Student Answer: We could have a multiprocessors and this could
let us increase parallelism -- multiple threads could run at the same time.
Instructor response: True, but this doesn't justify threads.
Multiple processes could run at the same time.
Answer (from class and instructor):
-
Fast communication: any thread can write to memory and any other thread
can see it -- without penalty.
-
Fast context switch: This actually depends on the implementation, but switching
among threads within the same address space is faster than switching among
processes in different address spaces. We don't need to save and restore
the context, including the BASE and LIMIT registers, and other memory-managment
registers, to context-switch. But depending on how the threads are implemented,
the amount of other overhead can varyy: it can be very, very fast, or just
somewhat faster.
-
A special cache, called the TLB doesn't need to be flushed to context switch
among threads in the same address space. This not only saves the time it
takes to flush the cache, but also maintains the utility of the cache --
this is a big win TLB misses are very expensive.
-
A process can do useful work, even while it is blocked: yes, but this also
depends on the implementation.
Kernel Supported Threads
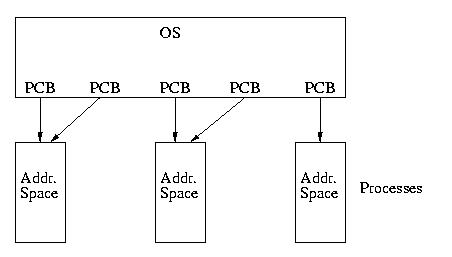
We can think of kernel supported threads as a system where multiple
PCBs can point to the same address space. Each PCB is really no longer
a PCB, but more of a thread control block (TCB). But it is still
usually called the PCB.
The PCB now maintains the state of each thread and allows each thead
to be scheduled independently. The PCB still holds the usual hardware state,
queue state, pointer to address state, and a pointer to the task control
block (TCB).
What is a TCB (notice that we are referring to a task control block,
not a thread control block)? It maintains the state that is not
stored in the PCB -- the state that applies to all threads.
We call processes composed of more than one thread of control tasks.
(This is the term we almost introduced earlier -- it just slipped)
This approach is consistent with the general computer science approach,
"anything in computer science can be solved with an additional level of
indirection." In this case the indirection via the TCB allows us to have
both common and separate state for the threads.
As the name implies, kernel supported threads require OS support. Many,
but not all, OSs support kernel threads.
User-level Threads
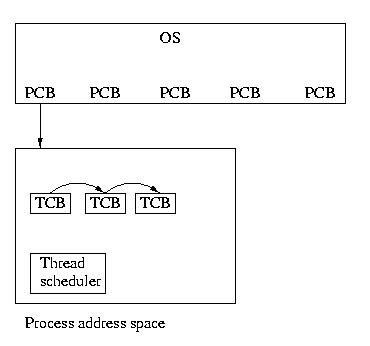
User-level threads are implemented via a user-level thread library.
The kernel niether knows nor cares that they exist. From the kernel's perspective,
they are just regular code. User level threads require no changes to the
kernel.
TCBs are simply malloc'd each time that a thread is created and linked
together to form queues -- within the space of the process.
Context switches among the threads are very cheap -- neither the hardware
nor the OS knows or cares about the context of the threads. Since we are
not changing address spaces or process state, we are not changing any registers.
The state of the threads is just part of the state of the process. This
saves much overhead.
Advantages of User-Level Threads
Context switches are cheaper, since no kernel support is required and
the state of the threads ispart of the state of the process.
No kernel support is required. user threads can be implemented by user
in older OSs that don't support kernel threads, or by more modern, but
minimalist OSs that also don't support kernel threads.
User-level threads can implement their own scheduling policy that may
be a better fit that the OS process scheduling policy.
Disadvantages of User-Level Threads
If one thread blocks, all threads within the process are blcoked. Example:
Reading from the terminal.
Student Question: Can't the threads use non-blocking writes?
Answer: yes, if the programming is careful to use signal-based,
non-blocking I/O.
Student Question: How can preemptive scheduling occur without
the timer interrupt?
Answer: This can all be simulated within a thread. In this case,
one way might be with SIGALRM.
Student Question: Couldn't the threads just yield to each other?
Answer: Yes, this could also work -- since they, unlike processes,
are cooperating by design.
Combination: Kernel and User-level Threads?
It is also possible to use a combination of user-level and kernel supported
threads. One open research area involves determining exotic ways of balancing
the use of both mechanisms.
CPU Scheduling
What are the goals of CPU scheduling? (This also applies to process
scheduling and CPU scheduling)
-
decrease the overhead of context-switching
-
decrease the overhead of the scheduler itself
-
Trade-off: making scheduling decisions more often allows more optimal decisions,
becuase the most up-to-date information is used. But running the scheduler
frequently increases the overhead of the scheduler itself. This is a tradeoff
between scheduling fairness and and decreasing the overhead of the scheduler.
-
decrease response time
-
increase throughput
Long-Term Scheduling
Long-term schedulign answers the question, "Which jobs are admitted
and when?" If too many jobs are scheduled, the system can begin to thrash
as it spends more time sharing resources than accomplishing useful work.
Good long term scheudling ensures that as many processes are run at a time
as is possible, without overburdening the system. The goal is to make 100%
utilization of resources by interleaving their use among processes -- without
making any resource (especially the CPU or memory) too scare to prevent
thrashing (or less-sever perfomrance degradation).
This is mostly used in batch systems, since, for example, we would
never want login to return "Too many users -- try again later."
Short-Term Scheduling (a.k.a CPU scheduling)
Short term schuling answers the question, which process gets the CPU.
This question is particularly important, because the CPU is the most valuable
resource in the system.
Medium-Term Scheduling
Medium-term scheduling is often implemented as part of memory management
(chapter 8).
Swapping, the movement of a parts of a process's memory to and
from disk, to free available RAM, is really medium term scheduling.
If too many processes are consuming too much memory, we keep moving
back and forth to disk. It is very expensive to move the same pages
to and from disk frequently. It might be better to run fewer processes
and keep more of their memory available.
The gola is to give processes the mimimum amount of memory that they
need to run efficiently. We can also swap processes to disk when they block
waiting for I/O. For example, the user doesn't need CPU while s/he is staring
at a prompt wondering what to type.
We'll talk about this topic in detail later.
Back To CPU Scheduling
There are many different types of scheduling. The first major distinction
that we will draw is between preemptive policies and non-preemptive
policies.
Premptive approaches allow the scheduler to stop a running process and
allow another process to run. With non-preemptive schuduling, once
a process starts, it will only be stopped if it voluntarily yields or if
it blocks. A stricter definition would require that it remain scheduled,
even if it blocked.
We'll start by discussing non-preemptive scheduling:
First Come First Serve (FCFS)
This is the "get in line approach." It is simple and in some sense fair.
But long jobs can force short jobs to wait a long time. It may be desirable
to run long jobs at night and short jobs during the day, or short jobs
first. FCFS can't enforce system priorities.
Shortest Job First(SJF)
SJF scheduling runs the job that requires the least CPU first. How do
we know which job this is?
In the past, the programmers on batch systems were required to describe
resource utilization on one for the first cards in the deck. If the over
specified the CPU use, wasting CPU, they would be penalized by a lower
priority.
If they underestimated the CPU use, their job wouldn't finish and they
would have to re-run the job. This provided incentive for good estimates.
Now systems might estimate CPU time based on the type of program, the
size of the input data set, &c. But these are just guesses. They might
be wrong.
This algorithm has the theoretical property that it has the minimal
average waiting time across all processes (if the CPU time is estimated
exactly). This is because the cost of a long job running first can penalize
many small jobs. But if the small jobs run first, only one job is
penalized. In other words, the same time penalty can be asmortized over
more jobs, if shorter jobs are run first.
But this algorithm is unfair and can lead to starvation. Longer jobs
might never run, if shorter jobs keep arriving.
Priority Scheduling
Priority based schuling is a generalization of either SJF or FCFS. Priority
based scheduling runs the highest priority jobs first. If we make shorter
jobs a higher priority than larger jobs, it is SJF. If we make older a
jobs higher prioirty than newer jobs, it is FCFS.
The priority can be anything. It can be derived from an econimic model.
for exmaple, the more you are willing to pay, the sooner your process will
get scheduled. This is equivalent to paying for Fed. Ex instead of gorund
shipping.
Or perhaps it could be assigned based on other concerns. Perhaps President
Cohen 's jobs get a higher priority than ours.
Preemptive Scheduling Is More Interesting
Premptive SJF
A preemptive of SJF would allow the scheduling decision of a process
to be re-evaluated based on new jobs that have arrived or based on the
quality of the estimate. If a shorter job arived, it could be run. Or if
the estimate proved to be inaccurate, and the expected completion time
increased, another job might be selected to run.
I/O and CPU bound jobs might be mixed to try to keep all of the I/O
devices busy. Estimates could be made of the CPU/IO burst cycle of the
processes and they could be scheduled accordingly. These estimates can
be adjusted based on past experience using averaging:
Let T0 be the initial guess
Let C1 be the initial measured value
T1, the next guess can be computed as follows:
T1 = (T0 + C1)/2
T1 = T0 alpha + C1 (1 - alpha)
0 < alpha < 1
Subsequent guess can be computed in a similar manner.
This leads to an adaptive evolution of the idea of the CPU/IO burst cycle
and an adaptive understanding of the process's priority.