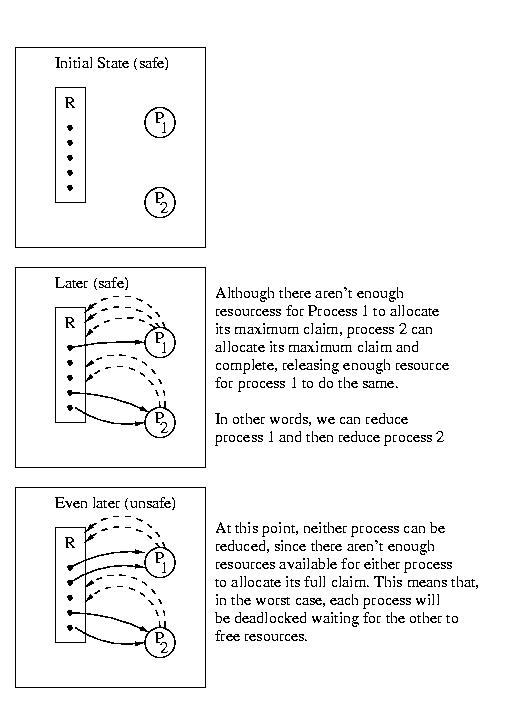
Deadlock Avoidance, continued.
The goal of deadlock avoidance is to always maintain the system in a safe
state. If we are careful, and we do, we can avoid deadlock.
To achieve this, we do the following each time a resource is requested:
Example:
2 processes
1 type of resource
5 instances of this resource (5 of them)
Max resource needs:
Process 1: 4
Process 2: 4
| Process 1 | Process 2 | Safe/Unsafe | |
|---|---|---|---|
| Initial state | 0 allocated | 0 allocated | safe |
| Later | 1 allocated | 2 allocated | safe |
| Even later | 2 allocated | 2 allocated | unsafe |
Memory Management (Chapter 8)
Review of Memory Management Hardware
There are two special purpose registers BASE and LIMIT such that
0 <= x < LIMIT, where x is any valid logical address, and
the physical address = BASE + x.
Let's Review: Why Multiprogram?
By overlapping CPU and I/O we can increase the utilization of the CPU. This
is because the CPU is not forced to idle while the currently active process
blocks for a much slower I/O device.
How can we run more processes at one time than fit in physical memory?
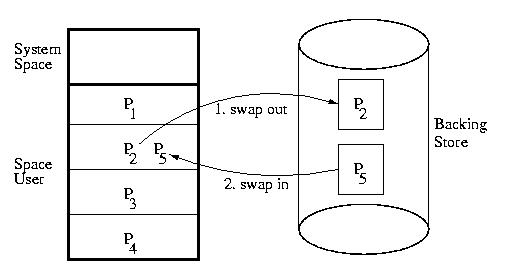
Swapping
Swapping works by copying an entire process at a time to and from disk.
Typically a processes is swapped out when it is expected to be blocked
for a long time.
Student Question: If the process is blocked for disk, swapping it out
doesn't do any good, right?
Answer: Older systems had special high-speed storage device dedicated
to swapping. Modern systems don't swap out processes because
they are waiting for a disk request. Instead they swap out
processes waiting for longer or less frequent events, such as
terminal requests or semaphores.
Technically, swap-space need not be a dedicated disk. It can be any of several media types. The secondary storage area used for swapping is called backing store:
Swapping and DMA: Ouch!
Swapping can cause problems for DMA operations. Remember that the DMA
controller has no understanding of process context. When a transfer
is intialized the DMA controller receives the base address and limit of the
transfer. If the process located about this space is swapped out and replaced
with another process, the DMA tranfer will continue unaffected. On read, the
result is damage to the current process as the DMA transfer scribbles on
top of the process space. On write the DMA transfer will corrupt the
output, by writing data from an unrelated address in a different process
into the output stream.
Student Question: Why not cache the DMA buffer?
Answer: Where? We don't have dedicted memory for this purpose.
Student Question: Since DMA requires a kernel call anyway, can't
we just mark the buffer space unswappable?
Answer: yes.
There are three solutions to this problem:
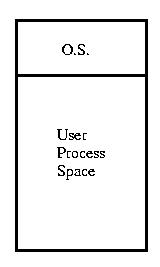
Memory Allocation: Single Partition Allocation
Older systems and embedded devices often simply divide memory
between a single process and the operating system. The only protection
required was to prevent the user process from scribbling in the system space.
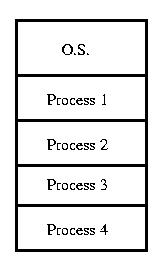
Memory Allocation: Multiple Fixed Partition Allocation
Another approach is to allow multiple fixed-sized chunks. Using this approach each process can use exactly one chunk. These chunks are of a predetermined fixed size. Depending on the details of the particular system, all chunks may be of the same size, or they me be one of several predetermined sizes. The bookkeeping required by this scheme is greatly reduced because the sizes of the chunks are fixed in advanced. But this approach wastes space, becuase a process may need less memory than in allocated in the best-fitting size. This type of wasted space is known as internal fragmentation. In this case, it is the price that we pay for simplicity.
Student Question: Does a process need to be swapped into the same chunk
that it previously occupied?
Answer: No a process can be swapped into any partition that is large
enough to hold it. The process only sees virtual addresses, not logical
addresses.
Memory Allocation: Multiple Variable Partition Allocation
Another approach might be to carve the space into partions on an as-needed basis. This approach complicates book keeping, but it eliminated internal fragmentation by ensuring that each process gets exactly as much space as is requested.
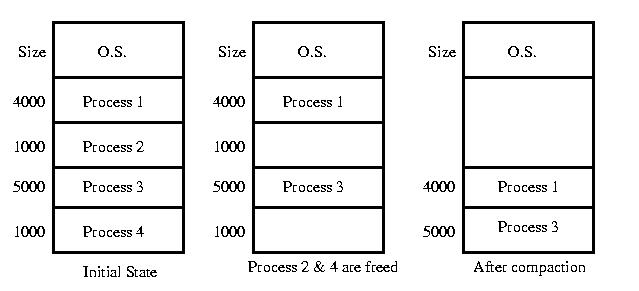
But this approach is not without its faults. Because the partitions are allocated and freed in arbitrary sizes, available memory can become broken into non-contiguous pieces. This leads to the situation where, although sufficient memory is available, no single partition can be created that is large enough to satisfy a request. This situation is known as external fragmentation.
The solution to external fragmentation is compaction. Compaction relocates processes within memory to collect all of the unallocated space in one area. This involves time-consuming copies, as well as adjusting the BASE register in each moved process's PCB. If an active process is being moved, the real registers must also be adjusted.
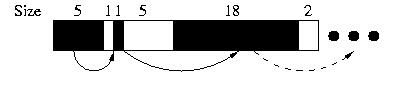
Memory Allocation Data Structures
Linked Lists (probably the most common)
The most popular approach is probably to use a linked list to keep track of memory allocations. Each node of the list contains the size and address of each chunk, and perhaps an "allocated" flag that indicates if the chunk is in use.
Sometimes we use a list to track only available memory. In other applications, lists can be used to free chunks, or both. If the list is sorted by address, free blocks can be coalesced.
struct chunk { char *addr; int size; bool allocated; struct chunks *next; };
Where Do I Store This Data Structure?
We can keep only a list of free chunks and then store this list inside of the free memory. This reduces overhead. The only memory that is wasted is the pointer to the head of the list.Power-of-2 Allocator
Another approach might be to restrict allocations to powers of two. Using this system, all allocations are rounded up to the nearest power of two. This causes some internal fragmentation, but reduces the external fragmentation caused by small chunks that are unlikely to be reallocated.